
Chris Hillman
Saturday, March 8, 2025
Leveraging LLMs for Business Impact: Part 2 - Building an AI Data Engineer Agent
Introduction
In Part 1 of this series, we explored the theoretical foundations of Large Language Models (LLMs), Retrieval Augmented Generation (RAG), and vector databases. Now, it’s time to put theory into practice. This is going to be a long read, so grab some coffee, and one (couple) of your favorite biscuits.
One use case for leveraging LLM’s, is creating of a Agent - a Senior Data Engineer AI that automatically reviews Pull Requests in your data engineering projects. This agent will be that nit picky Data Engineer that enforces SQL formatting standards, ensure naming and data type consistency, validate data quality checks, and suggest improvements based on best practices. By integrating this into your GitHub workflow, you can maintain higher code quality, accelerate onboarding for new team members, and reduce the burden of manual code reviews.
This tutorial walks through the complete implementation process from setting up the necessary API keys to crafting the AI agent and configuring GitHub Actions to run it automatically on every Pull Request.
Project Overview
Our AI-powered code review system will:
- Monitor GitHub for new Pull Requests in your data repository
- Extract changed files for analysis
- Retrieve relevant context about your code standards and existing codebase
- Analyze changes using a custom-prompted LLM
- Generate detailed feedback on code quality, standards compliance, and potential improvements
- Post review comments directly on the Pull Request
This solution combines GitHub APIs, LLM capabilities, and custom prompt engineering to create an automated reviewer that thinks like a senior data engineer on your team.

Although this does offer a solution, there is plenty of things that could be done to make this more robust, and far more superior. So please use this more for educational purposes, and a demonstration.
Use Cases and Benefits
This implementation addresses several key challenges in data engineering teams:
- Consistency Enforcement: Ensures all database objects follow the same naming conventions and data types
- Knowledge Transfer: Helps junior engineers learn best practices through contextual feedback
- Review Acceleration: Handles routine checks automatically, letting human reviewers focus on architecture and business logic
- Standards Documentation: Indirectly builds a living set of standards through consistent application
- Technical Debt Prevention: Catches potential issues before they enter the codebase
If setup correctly you can leverage a vector database to store context and improve for your business process over time.
Step 1: Setting Up the Required API Keys
To build our system, we’ll need authentication tokens for GitHub and an LLM provider. Here’s how to set these up securely:
GitHub Personal Access Token
- Log in to your GitHub account and navigate to Settings → Developer settings → Personal access tokens → Tokens (classic)
- Click Generate new token and select Generate new token (classic)
- Name your token something descriptive like “AI Code Reviewer”
- Set the expiration according to your needs
- Select the following permissions:
repo(Full control of private repositories)workflow(Update GitHub Action workflows)pull_requests(Access to pull requests)
- Click Generate token and copy the token immediately (you won’t be able to see it again)
LLM API Key
You’ll need access to a capable LLM. We’ll provide instructions for both Anthropic’s Claude and OpenAI’s GPT-4:
Anthropic Claude API Key:
- Visit Anthropic’s Console
- Create or log in to your account
- Navigate to API Keys in the left sidebar
- Click Create API Key
- Name your key (e.g., “GitHub Code Reviewer”)
- Copy and securely store your API key
OpenAI API Key (Alternative):
- Visit OpenAI’s Platform
- Sign in to your account
- Navigate to API Keys
- Click Create new secret key
- Name your key and click Create
- Copy and securely store the API key
Storing Secrets in GitHub Repository
Now we’ll add these secrets to your GitHub repository:
- Navigate to your repository on GitHub
- Go to Settings → Secrets and variables → Actions
- Click New repository secret
- Add the following secrets:
GH_TOKEN: Your GitHub Personal Access TokenANTHROPIC_API_KEYorOPENAI_API_KEY: Your LLM API key
These secrets will be accessible in our GitHub Actions workflow without being exposed in logs or to unauthorized users.
Step 2: Creating the AI Code Reviewer Script
We’ll create a Python script that pulls code from a PR, analyzes it with an LLM, and posts comments back to GitHub. Here’s the implementation:
import os
import requests
import json
import anthropic # or openai
import base64
from github import Github
from pathlib import Path
# Initialize clients
github_token = os.environ["GH_TOKEN"]
g = Github(github_token)
# Choose your LLM provider
USE_CLAUDE = True # Set to False to use OpenAI
if USE_CLAUDE:
anthropic_key = os.environ["ANTHROPIC_API_KEY"]
client = anthropic.Anthropic(api_key=anthropic_key)
else:
import openai
openai.api_key = os.environ["OPENAI_API_KEY"]
# GitHub repository information
repo_owner = os.environ["GITHUB_REPOSITORY_OWNER"]
repo_name = os.environ["GITHUB_REPOSITORY"].split("/")[1]
pr_number = int(os.environ["PR_NUMBER"])
repository = g.get_repo(f"{repo_owner}/{repo_name}")
pull_request = repository.get_pull(pr_number)
def get_sql_standards():
"""Retrieve SQL standards from repository documentation"""
standards = ""
try:
standards_file_content = repository.get_contents("docs/sql_standards.md")
standards = base64.b64decode(standards_file_content.content).decode("utf-8")
except:
# If no standards file exists, use default standards
standards = """
# SQL Standards
## Naming Conventions
- Tables: snake_case, plural (e.g., customer_orders)
- Columns: snake_case, singular (e.g., customer_id)
- Primary keys: id (e.g., customer_id)
- Foreign keys: Same name as referenced PK (e.g., customer_id)
- Boolean columns: is_* or has_* prefix (e.g., is_active)
- Date columns: _date suffix (e.g., created_date or created_date_id)
## Formatting
- Keywords in UPPERCASE
- Indentation of 4 spaces
- Commas at the end of lines
- One statement per line
## Data Types
- IDs: INTEGER or BIGINT
- Names: VARCHAR
- Flags: BOOLEAN
- Dates: DATE
- Timestamps: TIMESTAMP(6)
## DBT Practices
- Models must be idempotent
- Include appropriate tests for primary keys or unique keys
- Add descriptions to all models and columns
"""
return standards
def get_naming_dictionary():
"""Build a dictionary of standard column names and their data types from the codebase"""
naming_dict = {}
try:
# Check SQL and DBT files in the repository
sql_extensions = [".sql", ".yml"]
contents = repository.get_contents("")
# Process files recursively
while contents:
file_content = contents.pop(0)
if file_content.type == "dir":
contents.extend(repository.get_contents(file_content.path))
elif any(file_content.name.endswith(ext) for ext in sql_extensions):
# Extract DDL statements and column names
file_text = base64.b64decode(file_content.content).decode("utf-8")
# This is a simplified approach - a real implementation would use SQL parsing
for line in file_text.split("\n"):
if "CREATE TABLE" in line.upper() or "column:" in line.lower():
# Extract column definitions - this is simplified
if "INTEGER" in line.upper():
col_name = line.split()[0].strip(",").lower()
naming_dict[col_name] = "INTEGER"
elif "VARCHAR" in line.upper():
col_name = line.split()[0].strip(",").lower()
naming_dict[col_name] = "VARCHAR"
elif "DATE" in line.upper():
col_name = line.split()[0].strip(",").lower()
naming_dict[col_name] = "DATE"
# Add more data types as needed
except Exception as e:
print(f"Error building naming dictionary: {str(e)}")
# Add some default mappings if the dictionary is empty
if not naming_dict:
naming_dict = {
"account_number": "VARCHAR",
"customer_id": "VARCHAR",
"email_address": "VARCHAR",
"created_date": "DATE",
"is_active": "BOOLEAN",
"transaction_amount": "DECIMAL",
"product_name": "VARCHAR",
"order_id": "INTEGER"
}
return naming_dict
def analyze_file(file_path, file_content, sql_standards, naming_dict):
"""Submit file to LLM for analysis"""
# Construct the prompt for the LLM
prompt = f"""
You are an expert Senior Data Engineer responsible for reviewing SQL and data transformation code.
You're reviewing a pull request and need to provide detailed, actionable feedback.
# SQL STANDARDS AND BEST PRACTICES
{sql_standards}
# KNOWN COLUMN NAMING PATTERNS AND DATA TYPES
{json.dumps(naming_dict, indent=4)}
# FILE TO REVIEW
Path: {file_path}
```
{file_content}
```
Please review this code thoroughly and provide feedback on:
1. SQL formatting and adherence to our standards
2. Naming consistency (compared to our naming dictionary)
3. Data type consistency
4. Idempotency issues
5. Missing data quality checks or tests
6. Proper use of dbt_valid_from and dbt_valid_to for time-based models
7. Performance concerns
8. Any other issues or suggestions for improvement
Format your response as:
## Summary
A brief overview of the code quality (1-2 sentences)
## Issues
Describe each issue you find with line numbers and specific recommendations
## Suggestions
Provide constructive suggestions for improvement
## Proposed Tests
If relevant, suggest tests that would improve data quality
Focus on being helpful and educational. If something is done well, mention that too.
"""
# Call the appropriate LLM API
if USE_CLAUDE:
response = client.messages.create(
model="claude-3-opus-20240229",
max_tokens=4000,
temperature=0.2,
system="You are a Senior Data Engineer who specializes in code review. You provide constructive, specific feedback focused on data engineering best practices.",
messages=[
{"role": "user", "content": prompt}
]
)
return response.content[0].text
else:
response = openai.ChatCompletion.create(
model="gpt-4-turbo",
temperature=0.2,
messages=[
{"role": "system", "content": "You are a Senior Data Engineer who specializes in code review. You provide constructive, specific feedback focused on data engineering best practices."},
{"role": "user", "content": prompt}
]
)
return response.choices[0].message.content
def post_review_comment(pull_request, body):
"""Post a review comment to the pull request"""
try:
pull_request.create_issue_comment(body)
print(f"Posted review comment to PR #{pr_number}")
except Exception as e:
print(f"Error posting comment: {str(e)}")
def main():
# Get SQL standards and naming dictionary
sql_standards = get_sql_standards()
naming_dict = get_naming_dictionary()
# Get the files changed in the PR
files = pull_request.get_files()
# Track all feedback to post in one comment
all_feedback = f"# AI Data Engineer Review for PR #{pr_number}\n\n"
# Analyze each file
for file in files:
# Only process SQL and DBT files
if file.filename.endswith(('.sql', '.dbt', '.yml')):
print(f"Analyzing {file.filename}...")
file_content = requests.get(file.raw_url).text
# Analyze the file
feedback = analyze_file(file.filename, file_content, sql_standards, naming_dict)
all_feedback += f"## File: {file.filename}\n\n{feedback}\n\n---\n\n"
# Add a conclusion
all_feedback += """
**Note**: This review was generated by an AI assistant. While it strives for accuracy, always use your judgment when implementing suggestions.
If you have feedback on how to improve these automated reviews, please let us know!
"""
# Post the combined review
post_review_comment(pull_request, all_feedback)
if __name__ == "__main__":
main()
Let’s understand what this script does:
- It authenticates with GitHub and the LLM API of your choice (Claude or GPT-4)
- Extracts the SQL standards from your repository (or uses defaults)
- Builds a dictionary of common column names and data types from your codebase
- For each changed SQL or DBT file in the PR:
- Retrieves the file content
- Sends it to the LLM for analysis with a detailed prompt
- Collects the feedback
- Posts a comprehensive review comment to the PR
This script combines several powerful techniques:
- Contextual prompting: It gives the LLM your specific SQL standards and naming conventions
- Domain-specific guidance: The prompt focuses on data engineering concerns like idempotency and SCD tracking
- Actionable feedback: It asks for specific line numbers and recommendations
Step 3: Creating the GitHub Action Workflow
Now let’s set up the GitHub Action workflow to run this script automatically on every PR. Create a file at .github/workflows/ai-code-review.yml in your repository:
name: AI Data Engineer Code Review
on:
pull_request:
types: [opened, synchronize]
paths:
- '**.sql'
- '**/models/**.yml'
- '**/dbt_project.yml'
jobs:
review:
runs-on: ubuntu-latest
permissions:
contents: read
pull-requests: write
steps:
- name: Checkout repository
uses: actions/checkout@v3
with:
fetch-depth: 0
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: '3.10'
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install PyGithub requests anthropic openai
- name: Run AI code review
env:
GH_TOKEN: ${{ secrets.GH_TOKEN }}
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
PR_NUMBER: ${{ github.event.pull_request.number }}
GITHUB_REPOSITORY: ${{ github.repository }}
GITHUB_REPOSITORY_OWNER: ${{ github.repository_owner }}
run: |
# Create the code review script
cat > ai_code_review.py << 'EOF'
# Paste the entire Python script from Step 2 here
EOF
# Run the script
python ai_code_review.py
This workflow:
- Triggers whenever a PR is opened or updated
- Only runs when SQL, or YAML files are changed
- Sets up Python and installs the required dependencies
- Creates the review script (by embedding it in the workflow)
- Runs the script with the necessary environment variables
Step 4: Implementing RAG for Contextual Code Review
The real power of our AI code reviewer comes from using Retrieval Augmented Generation (RAG) to give the AI contextual understanding of your codebase, conventions, and standards. Rather than relying on hardcoded rules, we’ll build a vector database that understands your organization’s patterns and practices.
Here’s how we’ll approach this:
Creating and Maintaining a Vector Database of Codebase Knowledge
import os
import re
import numpy as np
import json
import base64
from datetime import datetime
import pinecone
from sentence_transformers import SentenceTransformer
# Initialize the embedding model
model = SentenceTransformer('all-MiniLM-L6-v2')
EMBEDDING_DIMENSION = 384 # Dimension for all-MiniLM-L6-v2
# Initialize Pinecone
PINECONE_API_KEY = os.environ.get("PINECONE_API_KEY")
PINECONE_ENVIRONMENT = os.environ.get("PINECONE_ENVIRONMENT", "gcp-starter")
INDEX_NAME = "data-engineer-reviewer"
pinecone.init(api_key=PINECONE_API_KEY, environment=PINECONE_ENVIRONMENT)
# Create index if it doesn't exist
if INDEX_NAME not in pinecone.list_indexes():
pinecone.create_index(
name=INDEX_NAME,
dimension=EMBEDDING_DIMENSION,
metric="cosine",
shards=1
)
# Connect to the index
index = pinecone.Index(INDEX_NAME)
def extract_code_knowledge(repository):
"""Extract and process knowledge from repository files"""
print("Beginning knowledge extraction from repository...")
# Lists to store our embeddings and metadata
sql_standards_data = []
naming_patterns_data = []
data_type_patterns_data = []
dbt_patterns_data = []
sql_files_processed = 0
# Get repository contents recursively
contents = repository.get_contents("")
sql_extensions = ['.sql', '.dbt', '.yml']
while contents:
file_content = contents.pop(0)
if file_content.type == "dir":
try:
dir_contents = repository.get_contents(file_content.path)
contents.extend(dir_contents)
except Exception as e:
print(f"Error accessing directory {file_content.path}: {str(e)}")
continue
elif any(file_content.path.endswith(ext) for ext in sql_extensions):
try:
# Process SQL and DBT files
file_text = base64.b64decode(file_content.content).decode("utf-8")
sql_files_processed += 1
# Extract column definitions and their data types
if file_content.path.endswith('.sql'):
# Extract table creation patterns
create_table_matches = re.findall(r"CREATE\s+TABLE\s+(\w+)\s*\((.*?)\)", file_text, re.DOTALL | re.IGNORECASE)
for table_name, columns_text in create_table_matches:
columns = columns_text.split(',')
for col in columns:
col = col.strip()
if col and not col.startswith('--'):
col_parts = col.split()
if len(col_parts) >= 2:
col_name = col_parts[0]
col_type = col_parts[1]
text = f"Column '{col_name}' is defined with data type '{col_type}' in table '{table_name}'"
embedding = model.encode(text).tolist()
data_type_patterns_data.append({
"id": f"dt_{col_name}_{sql_files_processed}",
"values": embedding,
"metadata": {
"text": text,
"column_name": col_name,
"data_type": col_type,
"file_path": file_content.path,
"source": "table_definition"
}
})
# Extract column references in SELECT statements
select_matches = re.findall(r"SELECT\s+(.*?)\s+FROM", file_text, re.DOTALL | re.IGNORECASE)
for select_clause in select_matches:
if '*' not in select_clause: # Skip SELECT *
columns = select_clause.split(',')
for col in columns:
col = col.strip()
if col and not col.startswith('--'):
# Handle aliasing with 'AS'
if ' AS ' in col.upper():
col_parts = col.split(' AS ', 1)
col_name = col_parts[1].strip()
else:
col_name = col.split('.')[-1].strip()
text = f"Column name '{col_name}' is used in SELECT statement in file {file_content.path}"
embedding = model.encode(text).tolist()
naming_patterns_data.append({
"id": f"np_{col_name}_{sql_files_processed}",
"values": embedding,
"metadata": {
"text": text,
"column_name": col_name,
"file_path": file_content.path,
"source": "select_statement"
}
})
# Extract DBT-specific patterns
if 'models/' in file_content.path or file_content.path.endswith('.yml'):
# Get a snippet of the file for context
text = file_text[:1000] # First 1000 chars for context
embedding = model.encode(text).tolist()
dbt_patterns_data.append({
"id": f"dbt_file_{sql_files_processed}",
"values": embedding,
"metadata": {
"text": text,
"file_path": file_content.path,
"source": "dbt_file"
}
})
# Look for specific DBT patterns
if '{{ config(' in file_text:
config_pattern = r"{{[\s]*config\((.*?)\)[\s]*}}"
config_matches = re.findall(config_pattern, file_text, re.DOTALL)
for config_content in config_matches:
text = f"DBT config in {file_content.path}: {config_content}"
embedding = model.encode(text).tolist()
dbt_patterns_data.append({
"id": f"dbt_config_{sql_files_processed}",
"values": embedding,
"metadata": {
"text": text,
"file_path": file_content.path,
"source": "dbt_config"
}
})
except Exception as e:
print(f"Error processing file {file_content.path}: {str(e)}")
# Extract SQL standards if they exist
try:
standards_file = repository.get_contents("docs/sql_standards.md")
standards_text = base64.b64decode(standards_file.content).decode("utf-8")
# Split into sections for better retrieval granularity
sections = re.split(r'#{2,3}\s+', standards_text)
for i, section in enumerate(sections):
if section.strip():
text = section.strip()
embedding = model.encode(text).tolist()
sql_standards_data.append({
"id": f"std_{i}",
"values": embedding,
"metadata": {
"text": text,
"source": "sql_standards",
"section_index": i
}
})
except:
# If no standards file, use some default standards
default_standards = [
"Use snake_case for all database object names",
"Primary keys should be named 'id' or 'table_name_id'",
"Foreign keys should match the referenced column name",
"Use UPPERCASE for SQL keywords",
"Indent with 2 spaces",
"Place each column on its own line in SELECT statements",
"Include a WHERE clause to avoid full table scans",
"Use consistent data types for similar fields across tables"
]
for i, standard in enumerate(default_standards):
embedding = model.encode(standard).tolist()
sql_standards_data.append({
"id": f"default_std_{i}",
"values": embedding,
"metadata": {
"text": standard,
"source": "default_standards",
"section_index": i
}
})
# Update the Pinecone index with the extracted knowledge
update_pinecone_index(sql_standards_data, naming_patterns_data, data_type_patterns_data, dbt_patterns_data)
print(f"Knowledge extraction complete. Processed {sql_files_processed} SQL files.")
print(f"Extracted: {len(sql_standards_data)} standard sections, {len(naming_patterns_data)} naming patterns, {len(data_type_patterns_data)} data type patterns, {len(dbt_patterns_data)} DBT patterns")
def update_pinecone_index(sql_standards, naming_patterns, data_type_patterns, dbt_patterns):
"""Update the Pinecone index with extracted knowledge"""
# Pinecone allows bulk upserts for better performance
# We'll tag vectors by their type for filtering later
# First, delete existing vectors by namespace
index.delete(delete_all=True, namespace="sql_standards")
index.delete(delete_all=True, namespace="naming_patterns")
index.delete(delete_all=True, namespace="data_types")
index.delete(delete_all=True, namespace="dbt_patterns")
# Upsert SQL standards data
if sql_standards:
index.upsert(vectors=sql_standards, namespace="sql_standards")
# Upsert naming patterns data
if naming_patterns:
# Pinecone has limits on batch size, so chunk if needed
chunk_size = 100
for i in range(0, len(naming_patterns), chunk_size):
chunk = naming_patterns[i:i + chunk_size]
index.upsert(vectors=chunk, namespace="naming_patterns")
# Upsert data type patterns
if data_type_patterns:
for i in range(0, len(data_type_patterns), chunk_size):
chunk = data_type_patterns[i:i + chunk_size]
index.upsert(vectors=chunk, namespace="data_types")
# Upsert DBT patterns
if dbt_patterns:
for i in range(0, len(dbt_patterns), chunk_size):
chunk = dbt_patterns[i:i + chunk_size]
index.upsert(vectors=chunk, namespace="dbt_patterns")
def query_repository_knowledge(query, namespace, top_k=5):
"""Query the Pinecone index for relevant knowledge"""
query_embedding = model.encode(query).tolist()
results = index.query(
vector=query_embedding,
top_k=top_k,
include_metadata=True,
namespace=namespace
)
# Extract the text from the metadata
if results.matches:
retrieved_texts = [match.metadata["text"] for match in results.matches]
return retrieved_texts
else:
return []
Then update the main() function to use our RAG-based approach:
def main():
# First, extract knowledge from the repository to build/update the vector database
# This could be done less frequently, such as on a schedule rather than for every PR
extract_code_knowledge(repository)
# Get the files changed in the PR
files = pull_request.get_files()
# Track all feedback to post in one comment
all_feedback = f"# AI Data Engineer Review for PR #{pr_number}\n\n"
# Initialize metrics summary
metrics = {
"files_analyzed": 0,
"issues_found": 0,
"naming_consistency_issues": 0,
"dbt_best_practice_issues": 0
}
# Analyze each file
for file in files:
# Only process SQL and DBT files
if file.filename.endswith(('.sql', '.dbt', '.yml')):
print(f"Analyzing {file.filename}...")
file_content = requests.get(file.raw_url).text
# Get primary feedback using RAG-powered analysis
primary_feedback = analyze_file(file.filename, file_content)
# Verify the feedback with a second agent
verification = verify_feedback(file.filename, file_content, primary_feedback)
# Analyze the review to identify specific categories of issues
issues_analysis = analyze_review_for_metrics(primary_feedback)
# Update metrics
metrics["files_analyzed"] += 1
metrics["issues_found"] += issues_analysis["total_issues"]
metrics["naming_consistency_issues"] += issues_analysis["naming_issues"]
metrics["dbt_best_practice_issues"] += issues_analysis["dbt_issues"]
# Combine feedback with verification
file_feedback = primary_feedback
if verification:
file_feedback += f"\n\n{verification}"
all_feedback += f"## File: {file.filename}\n\n{file_feedback}\n\n---\n\n"
# Add a conclusion
all_feedback += """
**Note**: This review was generated by an AI assistant. While it strives for accuracy, always use your judgment when implementing suggestions.
If you have feedback on how to improve these automated reviews, please let us know!
"""
# Post the combined review
post_review_comment(pull_request, all_feedback)
Also modify the analyze_file function to leverage this contextual knowledge:
def analyze_file(file_path, file_content):
"""Submit file to LLM for analysis using RAG context"""
# Build RAG context from the vector database
rag_context = build_rag_context_for_review(file_path, file_content)
# Construct the prompt for the LLM
prompt = f"""
You are an expert Senior Data Engineer responsible for reviewing SQL and data transformation code.
You're reviewing a pull request and need to provide detailed, actionable feedback.
# CONTEXT FROM CODEBASE ANALYSIS
{rag_context}
# FILE TO REVIEW
Path: {file_path}
```
{file_content}
```
Please review this code thoroughly based on the provided context. Focus your feedback on:
1. SQL formatting and adherence to our standards
2. Naming consistency with existing patterns in our codebase
3. Data type consistency with how we typically define these columns
4. Idempotency issues
5. Missing data quality checks or tests
6. If DBT code, proper use of dbt_valid_from and dbt_valid_to for time-based models
7. Performance concerns
8. Any other issues or suggestions for improvement
Format your response as:
## Summary
A brief overview of the code quality (1-2 sentences)
## Issues
Describe each issue you find with line numbers and specific recommendations
## Suggestions
Provide constructive suggestions for improvement
## Proposed Tests
If relevant, suggest tests that would improve data quality
Focus on being helpful and educational. If something is done well, mention that too.
"""
# Call the appropriate LLM API
if USE_CLAUDE:
response = client.messages.create(
model="claude-3-opus-20240229",
max_tokens=4000,
temperature=0,
system="You are a Senior Data Engineer who specializes in code review. You provide constructive, specific feedback focused on data engineering best practices.",
messages=[
{"role": "user", "content": prompt}
]
)
return response.content[0].text
else:
response = openai.ChatCompletion.create(
model="gpt-4",
temperature=0,
messages=[
{"role": "system", "content": "You are a Senior Data Engineer who specializes in code review. You provide constructive, specific feedback focused on data engineering best practices."},
{"role": "user", "content": prompt}
]
)
return response.choices[0].message.content
The function to build the RAG context for each review:
def build_rag_context_for_review(file_path, file_content):
"""Build a comprehensive RAG context for the file being reviewed"""
# Determine the type of file
is_sql = file_path.endswith('.sql')
is_dbt = 'models/' in file_path or file_path.endswith('.yml')
context_sections = []
# Always include SQL standards
sql_standards_results = query_repository_knowledge(
"SQL coding standards and best practices",
"sql_standards",
top_k=5
)
if sql_standards_results:
context_sections.append("# SQL STANDARDS AND BEST PRACTICES")
for doc in sql_standards_results:
context_sections.append(doc)
# Extract column names from the file to query for naming patterns
column_names = []
if is_sql:
# Simple regex to extract column names from SELECT statements
select_clauses = re.findall(r"SELECT\s+(.*?)\s+FROM", file_content, re.DOTALL | re.IGNORECASE)
for clause in select_clauses:
if '*' not in clause:
cols = clause.split(',')
for col in cols:
col = col.strip()
if ' AS ' in col.upper():
col = col.split(' AS ')[1].strip()
else:
col = col.split('.')[-1].strip()
column_names.append(col)
# Query for naming patterns information
if column_names:
naming_context = []
for col_name in column_names:
results = query_repository_knowledge(
f"Column named {col_name}",
"naming_patterns",
top_k=3
)
if results:
for doc in results:
naming_context.append(doc)
if naming_context:
context_sections.append("# COLUMN NAMING PATTERNS")
context_sections.extend(naming_context)
# Query for DBT patterns if applicable
if is_dbt:
dbt_context = []
# Look for specific DBT features in the file
dbt_features = []
if "{{ config(" in file_content:
dbt_features.append("DBT config block")
if "{{ ref(" in file_content:
dbt_features.append("DBT ref function")
if "{{ source(" in file_content:
dbt_features.append("DBT source function")
if "{{ dbt_utils" in file_content:
dbt_features.append("DBT utils package")
if "incremental" in file_content.lower():
dbt_features.append("incremental model")
for feature in dbt_features:
results = query_repository_knowledge(
f"DBT {feature} patterns and best practices",
"dbt_patterns",
top_k=3
)
if results:
for doc in results:
dbt_context.append(doc)
if dbt_context:
context_sections.append("# DBT PATTERNS AND BEST PRACTICES")
context_sections.extend(dbt_context)
# Combine all context sections
return "\n\n".join(context_sections)
This Pinecone implementation provides several advantages:
- Scalability: Pinecone can handle millions of vectors and high query throughput
- Managed Service: No need to worry about infrastructure management
- Low Latency: Optimized for fast query responses
- Namespaces: Built-in support for organizing vectors by category (SQL standards, naming patterns, etc.)
Using this RAG approach with Pinecone gives the AI reviewer true contextual awareness of your specific codebase patterns and standards without the need for hardcoded rules.
Step 5: Adding Multi-Agent Verification for Improved Reliability
To reduce hallucinations and improve the reliability of our reviews, we can implement a multi-agent verification system that uses a second “Critic” agent to verify the primary agent’s findings:
def verify_feedback(file_path, file_content, primary_feedback):
"""
Use a second LLM as a "Critic" to verify the primary agent's feedback
and reduce hallucinations
"""
# Build a simpler RAG context focused on verifying factual claims
file_type = "SQL" if file_path.endswith('.sql') else "DBT" if 'models/' in file_path else "YAML" if file_path.endswith('.yml') else "Other"
verification_prompt = f"""
You are a Critical Reviewer whose job is to verify another AI's code review for accuracy.
You should check if the review is factually correct and relevant to the code.
# FILE REVIEWED ({file_type})
Path: {file_path}
```
{file_content}
```
# ORIGINAL REVIEW
{primary_feedback}
Please verify this review and note:
1. Any hallucinations or incorrect statements about the code
2. Any misinterpretations of SQL syntax or data engineering concepts
3. Any feedback that seems contradictory or inconsistent
Only mention issues that are clearly wrong - do not repeat correct feedback.
If the review seems accurate, just say "The review appears accurate."
"""
def analyze_review_for_metrics(review_text):
"""Analyze the review content to extract metrics about issues found"""
analysis = {
"total_issues": 0,
"naming_issues": 0,
"data_type_issues": 0,
"performance_issues": 0,
"dbt_issues": 0,
"test_issues": 0,
"formatting_issues": 0
}
# Count total issues by looking for "##" sections
issues_section = re.search(r"## Issues\s+(.*?)(?=##|$)", review_text, re.DOTALL)
if issues_section:
issues_text = issues_section.group(1)
# Count bullet points or numbered items
items = re.findall(r"^(?:\d+\.|-|\*)\s+", issues_text, re.MULTILINE)
analysis["total_issues"] = len(items)
# Check for naming-related issues
if re.search(r"naming|column name|inconsistent", review_text, re.IGNORECASE):
naming_matches = re.findall(r"naming|column name|inconsistent", review_text, re.IGNORECASE)
analysis["naming_issues"] = len(naming_matches)
# Check for data type issues
if re.search(r"data type|varchar|integer|decimal|timestamp", review_text, re.IGNORECASE):
data_type_matches = re.findall(r"data type|varchar|integer|decimal|timestamp", review_text, re.IGNORECASE)
analysis["data_type_issues"] = len(data_type_matches)
# Check for performance issues
if re.search(r"performance|slow|optimization|index|partition", review_text, re.IGNORECASE):
performance_matches = re.findall(r"performance|slow|optimization|index|partition", review_text, re.IGNORECASE)
analysis["performance_issues"] = len(performance_matches)
# Check for DBT-specific issues
if re.search(r"dbt|incremental|model|materialization|ref|source", review_text, re.IGNORECASE):
dbt_matches = re.findall(r"dbt|incremental|model|materialization|ref|source", review_text, re.IGNORECASE)
analysis["dbt_issues"] = len(dbt_matches)
# Check for test-related issues
if re.search(r"test|assert|validation|quality", review_text, re.IGNORECASE):
test_matches = re.findall(r"test|assert|validation|quality", review_text, re.IGNORECASE)
analysis["test_issues"] = len(test_matches)
# Check for formatting issues
if re.search(r"format|indent|spaces|uppercase|lowercase", review_text, re.IGNORECASE):
formatting_matches = re
# Call the LLM API (using a different model if possible)
if USE_CLAUDE:
response = client.messages.create(
model="claude-3-sonnet-20240229", # Using a different model
max_tokens=2000,
temperature=0,
system="You are a Critical Reviewer who verifies the accuracy of code reviews. You only point out factual errors and hallucinations.",
messages=[
{"role": "user", "content": verification_prompt}
]
)
verification = response.content[0].text
else:
response = openai.ChatCompletion.create(
model="gpt-4-turbo",
temperature=0,
messages=[
{"role": "system", "content": "You are a Critical Reviewer who verifies the accuracy of code reviews. You only point out factual errors and hallucinations."},
{"role": "user", "content": verification_prompt}
]
)
verification = response.choices[0].message.content
# Only include verification notes if issues were found
if "appears accurate" not in verification.lower():
return f"""
## Verification Notes
{verification}
"""
return ""
Then update the main function to include this verification step:
def build_rag_context_for_review(file_path, file_content):
"""Build a comprehensive RAG context for the file being reviewed"""
# Determine the type of file and construct appropriate queries
is_sql = file_path.endswith('.sql')
is_dbt = 'models/' in file_path or file_path.endswith('.yml')
context_sections = []
# Always include SQL standards
sql_standards_results = query_repository_knowledge(
"SQL coding standards and best practices",
"sql_standards",
top_k=5
)
if sql_standards_results["documents"]:
context_sections.append("# SQL STANDARDS AND BEST PRACTICES")
for doc in sql_standards_results["documents"][0]:
context_sections.append(doc)
# Extract column names from the file to query for naming patterns
column_names = []
if is_sql:
# Simple regex to extract column names from SELECT statements
# In a production system, use a proper SQL parser
select_clauses = re.findall(r"SELECT\s+(.*?)\s+FROM", file_content, re.DOTALL | re.IGNORECASE)
for clause in select_clauses:
if '*' not in clause:
cols = clause.split(',')
for col in cols:
col = col.strip()
if ' AS ' in col.upper():
col = col.split(' AS ')[1].strip()
else:
col = col.split('.')[-1].strip()
column_names.append(col)
# Also extract from CREATE TABLE statements
create_table_matches = re.findall(r"CREATE\s+TABLE\s+\w+\s*\((.*?)\)", file_content, re.DOTALL | re.IGNORECASE)
for columns_text in create_table_matches:
cols = columns_text.split(',')
for col in cols:
col = col.strip()
if col and not col.startswith('--'):
col_parts = col.split()
if len(col_parts) >= 2:
column_names.append(col_parts[0])
# Query for naming patterns information
if column_names:
naming_context = []
for col_name in column_names:
results = query_repository_knowledge(
f"Column named {col_name}",
"naming_patterns",
top_k=3
)
if results["documents"] and results["documents"][0]:
for doc in results["documents"][0]:
naming_context.append(doc)
if naming_context:
context_sections.append("# COLUMN NAMING PATTERNS")
context_sections.extend(naming_context)
# Query for data type information
if column_names:
data_type_context = []
for col_name in column_names:
results = query_repository_knowledge(
f"Data type for column {col_name}",
"data_types",
top_k=3
)
if results["documents"] and results["documents"][0]:
for doc in results["documents"][0]:
data_type_context.append(doc)
if data_type_context:
context_sections.append("# DATA TYPE PATTERNS")
context_sections.extend(data_type_context)
# Query for DBT patterns if applicable
if is_dbt:
dbt_context = []
# Look for specific DBT features in the file
dbt_features = []
if "{{ config(" in file_content:
dbt_features.append("DBT config block")
if "{{ ref(" in file_content:
dbt_features.append("DBT ref function")
if "{{ source(" in file_content:
dbt_features.append("DBT source function")
if "{{ dbt_utils" in file_content:
dbt_features.append("DBT utils package")
if "incremental" in file_content.lower():
dbt_features.append("incremental model")
for feature in dbt_features:
results = query_repository_knowledge(
f"DBT {feature} patterns and best practices",
"dbt_patterns",
top_k=3
)
if results["documents"] and results["documents"][0]:
for doc in results["documents"][0]:
dbt_context.append(doc)
if dbt_context:
context_sections.append("# DBT PATTERNS AND BEST PRACTICES")
context_sections.extend(dbt_context)
# Combine all context sections
return "\n\n".join(context_sections)
def main():
# First, extract knowledge from the repository to build/update the vector database
# This could be done less frequently, such as on a schedule rather than for every PR
extract_code_knowledge(repository)
# Get the files changed in the PR
files = pull_request.get_files()
# Track all feedback to post in one comment
all_feedback = f"# AI Data Engineer Review for PR #{pr_number}\n\n"
# Initialize metrics summary
metrics = {
"files_analyzed": 0,
"issues_found": 0,
"naming_consistency_issues": 0,
"dbt_best_practice_issues": 0
}
# Analyze each file
for file in files:
# Only process SQL and DBT files
if file.filename.endswith(('.sql', '.dbt', '.yml')):
print(f"Analyzing {file.filename}...")
file_content = requests.get(file.raw_url).text
# Get primary feedback
primary_feedback = analyze_file(file.filename, file_content, sql_standards, naming_dict, repo_context)
# Verify the feedback
verification = verify_feedback(file.filename, file_content, primary_feedback, sql_standards)
# Check custom rules
custom_issues = check_custom_rules(file_content)
# Analyze naming consistency
consistency_result = analyze_naming_consistency(file_content, naming_dict)
# Build custom rules and metrics section
custom_section = ""
if custom_issues or consistency_result["inconsistent_columns"]:
custom_section = "## Custom Rules and Metrics\n\n"
custom_section += f"**Naming Consistency Score**: {consistency_result['score']}%\n\n"
if consistency_result["inconsistent_columns"]:
custom_section += "**Inconsistent Column Names/Types**:\n"
for col in consistency_result["inconsistent_columns"]:
custom_section += f"- {col}\n"
custom_section += "\n"
if custom_issues:
custom_section += "**Custom Rule Violations**:\n"
for issue in custom_issues:
custom_section += f"- {issue}\n"
custom_section += "\n"
# Combine all feedback sections
file_feedback = primary_feedback
if custom_section:
file_feedback += f"\n\n{custom_section}"
if verification:
file_feedback += f"\n\n{verification}"
# Update metrics
metrics["files_analyzed"] += 1
metrics["issues_found"] += len(custom_issues)
metrics["avg_naming_consistency"] += consistency_result["score"]
metrics["custom_rule_violations"] += len(custom_issues)
all_feedback += f"## File: {file.filename}\n\n{file_feedback}\n\n---\n\n"
# Calculate average naming consistency
if metrics["files_analyzed"] > 0:
metrics["avg_naming_consistency"] /= metrics["files_analyzed"]
# Add metrics summary
metrics_summary = f"""
## Review Metrics
- Files Analyzed: {metrics["files_analyzed"]}
- Issues Found: {metrics["issues_found"]}
- Average Naming Consistency: {metrics["avg_naming_consistency"]:.1f}%
- Custom Rule Violations: {metrics["custom_rule_violations"]}
"""
all_feedback += metrics_summary
# Add a conclusion
all_feedback += """
**Note**: This review was generated by an AI assistant. While it strives for accuracy, always use your judgment when implementing suggestions.
If you have feedback on how to improve these automated reviews, please let us know!
"""
# Post the combined review
post_review_comment(pull_request, all_feedback)
This multi-agent approach helps ensure that the reviews your team receives are more accurate and reliable. The second agent acts as a fact-checker, flagging any hallucinations or misinterpretations.
Step 6: Implementing GitHub Action Using Your Existing Framework
Now that we’ve established our vector database for contextual code reviews, let’s integrate it with GitHub Actions using your existing framework. We’ll build on the generate_comment.py script and autofeedback.yml workflow you’ve already created.
First, let’s update the generate_comment.py file to use our RAG-powered approach:
import os
import sys
import requests
import logging
import re
import base64
import pinecone
from openai import OpenAI
from github import Github
from sentence_transformers import SentenceTransformer
# Setup logging
logger = logging.getLogger()
formatter = logging.Formatter("%(message)s")
stream_handler = logging.StreamHandler(sys.stdout)
stream_handler.setFormatter(formatter)
logger.addHandler(stream_handler)
logger.setLevel(logging.INFO)
# Environment variables
GIT_TOKEN = os.environ.get('GIT_TOKEN')
GIT_REPO = os.environ.get('GITHUB_REPOSITORY')
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")
PINECONE_API_KEY = os.environ.get("PINECONE_API_KEY")
PINECONE_ENVIRONMENT = os.environ.get("PINECONE_ENVIRONMENT", "gcp-starter")
if OPENAI_API_KEY is None:
raise ValueError("You need to specify OPENAI_API_KEY environment variable!")
if PINECONE_API_KEY is None:
raise ValueError("You need to specify PINECONE_API_KEY environment variable!")
# Initialize OpenAI client
client = OpenAI(api_key=OPENAI_API_KEY)
# Initialize embedding model
model = SentenceTransformer('all-MiniLM-L6-v2')
EMBEDDING_DIMENSION = 384 # Dimension for all-MiniLM-L6-v2
# Initialize Pinecone
INDEX_NAME = "data-engineer-reviewer"
pinecone.init(api_key=PINECONE_API_KEY, environment=PINECONE_ENVIRONMENT)
# Create index if it doesn't exist
if INDEX_NAME not in pinecone.list_indexes():
pinecone.create_index(
name=INDEX_NAME,
dimension=EMBEDDING_DIMENSION,
metric="cosine",
shards=1
)
# Connect to the index
index = pinecone.Index(INDEX_NAME)
def get_pr_info(pr_number):
"""Get PR files and information"""
g = Github(GIT_TOKEN)
repo = g.get_repo(GIT_REPO)
pr = repo.get_pull(pr_number)
files = pr.get_files()
# Filter for data engineering files
data_files = [f for f in files if f.filename.endswith(('.sql', '.yml', '.dbt'))]
return {
"pr": pr,
"repo": repo,
"data_files": data_files
}
def extract_repository_knowledge(repo):
"""Extract knowledge from the repository to populate the vector database"""
logger.info("Extracting knowledge from repository...")
# Lists to store our embeddings and metadata
sql_standards_data = []
naming_patterns_data = []
data_type_patterns_data = []
dbt_patterns_data = []
# First, try to find SQL standards document
try:
standards_file = repo.get_contents("docs/sql_standards.md")
standards_text = base64.b64decode(standards_file.content).decode("utf-8")
# Split into sections for better retrieval granularity
sections = re.split(r'#{2,3}\s+', standards_text)
for i, section in enumerate(sections):
if section.strip():
text = section.strip()
embedding = model.encode(text).tolist()
sql_standards_data.append({
"id": f"std_{i}",
"values": embedding,
"metadata": {
"text": text,
"source": "sql_standards",
"section_index": i
}
})
logger.info(f"Found SQL standards document with {len(sections)} sections")
except:
# If no standards file, use default standards
logger.info("No SQL standards document found, using defaults")
default_standards = [
"Use snake_case for all database object names",
"Primary keys should be named 'id' or 'table_name_id'",
"Foreign keys should match the referenced column name",
"Use UPPERCASE for SQL keywords",
"Indent with 2 spaces",
"Place each column on its own line in SELECT statements",
"Include a WHERE clause to avoid full table scans",
"Use consistent data types for similar fields across tables"
]
for i, standard in enumerate(default_standards):
embedding = model.encode(standard).tolist()
sql_standards_data.append({
"id": f"default_std_{i}",
"values": embedding,
"metadata": {
"text": standard,
"source": "default_standards",
"section_index": i
}
})
# Find existing models and their patterns
try:
# Look for DBT models directory
models_contents = repo.get_contents("models")
model_files = []
# Recursive function to collect all SQL files
def collect_sql_files(contents):
for item in contents:
if item.type == "dir":
collect_sql_files(repo.get_contents(item.path))
elif item.path.endswith(('.sql', '.yml')):
model_files.append(item)
collect_sql_files(models_contents)
logger.info(f"Found {len(model_files)} model files to analyze")
# Sample a subset of files to analyze (to avoid API rate limits)
file_sample = model_files[:50] # Adjust based on your needs
for file_content in file_sample:
try:
file_text = base64.b64decode(file_content.content).decode("utf-8")
# Extract column information from SQL files
if file_content.path.endswith('.sql'):
# Extract column references in SELECT statements
select_matches = re.findall(r"SELECT\s+(.*?)\s+FROM", file_text, re.DOTALL | re.IGNORECASE)
for select_clause in select_matches:
if '*' not in select_clause: # Skip SELECT *
columns = select_clause.split(',')
for col in columns:
col = col.strip()
if col and not col.startswith('--'):
# Handle aliasing with 'AS'
if ' AS ' in col.upper():
col_parts = col.split(' AS ', 1)
col_name = col_parts[1].strip()
else:
col_name = col.split('.')[-1].strip()
text = f"Column name '{col_name}' is used in SELECT statement in file {file_content.path}"
embedding = model.encode(text).tolist()
naming_patterns_data.append({
"id": f"np_{col_name}_{len(naming_patterns_data)}",
"values": embedding,
"metadata": {
"text": text,
"column_name": col_name,
"file_path": file_content.path,
"source": "select_statement"
}
})
# Extract DBT-specific patterns
if 'models/' in file_content.path:
# Get a snippet of the file for context
text = file_text[:1000] # First 1000 chars for context
embedding = model.encode(text).tolist()
dbt_patterns_data.append({
"id": f"dbt_file_{len(dbt_patterns_data)}",
"values": embedding,
"metadata": {
"text": text,
"file_path": file_content.path,
"source": "dbt_file"
}
})
# Look for specific DBT patterns
if '{{ config(' in file_text:
config_pattern = r"{{[\s]*config\((.*?)\)[\s]*}}"
config_matches = re.findall(config_pattern, file_text, re.DOTALL)
for config_content in config_matches:
text = f"DBT config in {file_content.path}: {config_content}"
embedding = model.encode(text).tolist()
dbt_patterns_data.append({
"id": f"dbt_config_{len(dbt_patterns_data)}",
"values": embedding,
"metadata": {
"text": text,
"file_path": file_content.path,
"source": "dbt_config"
}
})
except Exception as e:
logger.error(f"Error processing file {file_content.path}: {str(e)}")
except Exception as e:
logger.warning(f"Could not process models directory: {str(e)}")
# Update the Pinecone index with the extracted knowledge
update_pinecone_index(sql_standards_data, naming_patterns_data, data_type_patterns_data, dbt_patterns_data)
logger.info(f"Knowledge extraction complete.")
logger.info(f"Indexed: {len(sql_standards_data)} standard sections, {len(naming_patterns_data)} naming patterns, {len(data_type_patterns_data)} data type patterns, {len(dbt_patterns_data)} DBT patterns")
def update_pinecone_index(sql_standards, naming_patterns, data_type_patterns, dbt_patterns):
"""Update the Pinecone index with extracted knowledge"""
# First, delete existing vectors by namespace
try:
index.delete(delete_all=True, namespace="sql_standards")
index.delete(delete_all=True, namespace="naming_patterns")
index.delete(delete_all=True, namespace="data_types")
index.delete(delete_all=True, namespace="dbt_patterns")
# Upsert SQL standards data
if sql_standards:
index.upsert(vectors=sql_standards, namespace="sql_standards")
# Upsert naming patterns data
if naming_patterns:
# Pinecone has limits on batch size, so chunk if needed
chunk_size = 100
for i in range(0, len(naming_patterns), chunk_size):
chunk = naming_patterns[i:i + chunk_size]
index.upsert(vectors=chunk, namespace="naming_patterns")
# Upsert data type patterns
if data_type_patterns:
for i in range(0, len(data_type_patterns), chunk_size):
chunk = data_type_patterns[i:i + chunk_size]
index.upsert(vectors=chunk, namespace="data_types")
# Upsert DBT patterns
if dbt_patterns:
for i in range(0, len(dbt_patterns), chunk_size):
chunk = dbt_patterns[i:i + chunk_size]
index.upsert(vectors=chunk, namespace="dbt_patterns")
except Exception as e:
logger.error(f"Error updating Pinecone index: {str(e)}")
def query_repository_knowledge(query, namespace, top_k=5):
"""Query the Pinecone index for relevant knowledge"""
query_embedding = model.encode(query).tolist()
try:
results = index.query(
vector=query_embedding,
top_k=top_k,
include_metadata=True,
namespace=namespace
)
# Extract the text from the metadata
if results.matches:
retrieved_texts = [match.metadata["text"] for match in results.matches]
return retrieved_texts
else:
return []
except Exception as e:
logger.error(f"Error querying Pinecone: {str(e)}")
return []
def build_rag_context_for_review(file_path, file_content):
"""Build a comprehensive RAG context for the file being reviewed"""
# Determine the type of file
is_sql = file_path.endswith('.sql')
is_dbt = 'models/' in file_path or file_path.endswith('.yml')
context_sections = []
# Always include SQL standards
sql_standards_results = query_repository_knowledge(
"SQL coding standards and best practices",
"sql_standards",
top_k=5
)
if sql_standards_results:
context_sections.append("# SQL STANDARDS AND BEST PRACTICES")
for doc in sql_standards_results:
context_sections.append(doc)
# Extract column names from the file to query for naming patterns
column_names = []
if is_sql:
# Simple regex to extract column names from SELECT statements
select_clauses = re.findall(r"SELECT\s+(.*?)\s+FROM", file_content, re.DOTALL | re.IGNORECASE)
for clause in select_clauses:
if '*' not in clause:
cols = clause.split(',')
for col in cols:
col = col.strip()
if ' AS ' in col.upper():
col = col.split(' AS ')[1].strip()
else:
col = col.split('.')[-1].strip()
column_names.append(col)
# Query for naming patterns information
if column_names:
naming_context = []
for col_name in column_names:
results = query_repository_knowledge(
f"Column named {col_name}",
"naming_patterns",
top_k=3
)
if results:
for doc in results:
naming_context.append(doc)
if naming_context:
context_sections.append("# COLUMN NAMING PATTERNS")
context_sections.extend(naming_context)
# Query for DBT patterns if applicable
if is_dbt:
dbt_context = []
# Look for specific DBT features in the file
dbt_features = []
if "{{ config(" in file_content:
dbt_features.append("DBT config block")
if "{{ ref(" in file_content:
dbt_features.append("DBT ref function")
if "{{ source(" in file_content:
dbt_features.append("DBT source function")
if "{{ dbt_utils" in file_content:
dbt_features.append("DBT utils package")
if "incremental" in file_content.lower():
dbt_features.append("incremental model")
for feature in dbt_features:
results = query_repository_knowledge(
f"DBT {feature} patterns and best practices",
"dbt_patterns",
top_k=3
)
if results:
for doc in results:
dbt_context.append(doc)
if dbt_context:
context_sections.append("# DBT PATTERNS AND BEST PRACTICES")
context_sections.extend(dbt_context)
# Combine all context sections
return "\n\n".join(context_sections)
def get_feedback(file_path, file_content):
"""Generate AI review feedback using RAG context"""
# Build RAG context from the vector database
rag_context = build_rag_context_for_review(file_path, file_content)
# System prompt for the Senior Data Engineer persona
system_prompt = """
You are an expert Senior Data Engineer responsible for reviewing SQL and data transformation code.
You have extensive knowledge of SQL, DBT, data modeling, and data engineering best practices.
Your feedback should be detailed, specific, and constructive, focusing on:
1. SQL formatting and adherence to standards
2. Naming consistency with existing patterns
3. Data type consistency
4. Idempotency issues
5. Missing data quality checks or tests
6. Proper time-based modeling (SCD) implementation
7. Performance optimization opportunities
Always provide line numbers and specific suggestions for improvement.
"""
# User prompt with the RAG context and file to review
user_prompt = f"""
I need you to review a data engineering file. Here's some context about our codebase standards and patterns:
{rag_context}
# FILE TO REVIEW
Path: {file_path}
```
{file_content}
```
Please provide a comprehensive review focusing on:
1. SQL formatting and adherence to our standards
2. Naming consistency with existing patterns in our codebase
3. Data type consistency with how we typically define these columns
4. Idempotency issues
5. Missing data quality checks or tests
6. If it's DBT code, proper use of dbt_valid_from and dbt_valid_to for time-based models
7. Performance concerns
Format your response as:
## Summary
A brief overview of the code quality (1-2 sentences)
## Issues
Describe each issue you find with line numbers and specific recommendations
## Suggestions
Provide constructive suggestions for improvement
## Proposed Tests
If relevant, suggest tests that would improve data quality
"""
try:
# Call the OpenAI API
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
],
temperature=0,
)
# Get the review content
review = response.choices[0].message.content
# Format as a GitHub comment
comment = f"# Senior Data Engineer Review for `{file_path}`\n\n{review}\n\n---\n\n*This automated review was generated using AI and repository knowledge. If you have feedback on improving these reviews, please let the team know!*"
return comment
except Exception as e:
logger.error(f"Error generating review: {str(e)}")
return f"Error generating review for `{file_path}`: {str(e)}"
def post_github_comment(pr, comment):
"""Post a comment to the GitHub PR"""
try:
pr.create_issue_comment(comment)
logger.info(f"✅ Posted review comment to PR #{pr.number}")
return True
except Exception as e:
logger.error(f"Error posting comment: {str(e)}")
return False
def main(pr_number):
"""Main function to process PR and generate reviews"""
logger.info(f"Starting review process for PR #{pr_number}")
# Get PR information
pr_info = get_pr_info(pr_number)
if not pr_info["data_files"]:
logger.info("No SQL, YML, or DBT files found in this PR. Skipping review.")
return
# Extract knowledge from repository to build or update vector database
# This could be done less frequently in production
extract_repository_knowledge(pr_info["repo"])
# Process each data file in the PR
for file in pr_info["data_files"]:
logger.info(f"Reviewing file: {file.filename}")
try:
# Get file content
file_content = requests.get(file.raw_url).text
# Generate AI review feedback
review_comment = get_feedback(file.filename, file_content)
# Post comment to PR
post_github_comment(pr_info["pr"], review_comment)
except Exception as e:
logger.error(f"Error processing {file.filename}: {str(e)}")
if __name__ == "__main__":
if len(sys.argv) < 2:
logger.error("PR number is required as an argument")
sys.exit(1)
pr_number = int(sys.argv[1])
main(pr_number)
Next, let’s update the GitHub Actions workflow file (autofeedback.yml) to include the Pinecone API key and install the necessary dependencies:
name: Senior Data Engineer AI Review
on:
pull_request:
types: [opened, synchronize]
paths:
- '**.sql'
- '**/models/**.yml'
- '**/dbt_project.yml'
jobs:
review:
runs-on: ubuntu-latest
permissions:
contents: read
pull-requests: write
steps:
- name: Checkout code
uses: actions/checkout@v2
with:
fetch-depth: 0 # Fetch all history to analyze codebase
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.10'
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install PyGithub requests openai pinecone-client sentence-transformers
- name: Run Data Engineer AI Review
env:
GIT_TOKEN: ${{ secrets.GIT_TOKEN }}
GITHUB_REPOSITORY: ${{ github.repository }}
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
PINECONE_API_KEY: ${{ secrets.PINECONE_API_KEY }}
PINECONE_ENVIRONMENT: ${{ secrets.PINECONE_ENVIRONMENT }}
run: |
python src/generate_comment.py ${{ github.event.pull_request.number }}
Finally, create a requirements.txt file to ensure all dependencies are installed:
Setting Up the Secrets
For this implementation to work, you’ll need to add these secrets to your GitHub repository:
- Navigate to your repository on GitHub
- Go to Settings → Secrets and variables → Actions
- Add the following secrets:
GIT_TOKEN: Your GitHub Personal Access TokenOPENAI_API_KEY: Your OpenAI API keyPINECONE_API_KEY: Your Pinecone API keyPINECONE_ENVIRONMENT: Your Pinecone environment (e.g., “gcp-starter”)
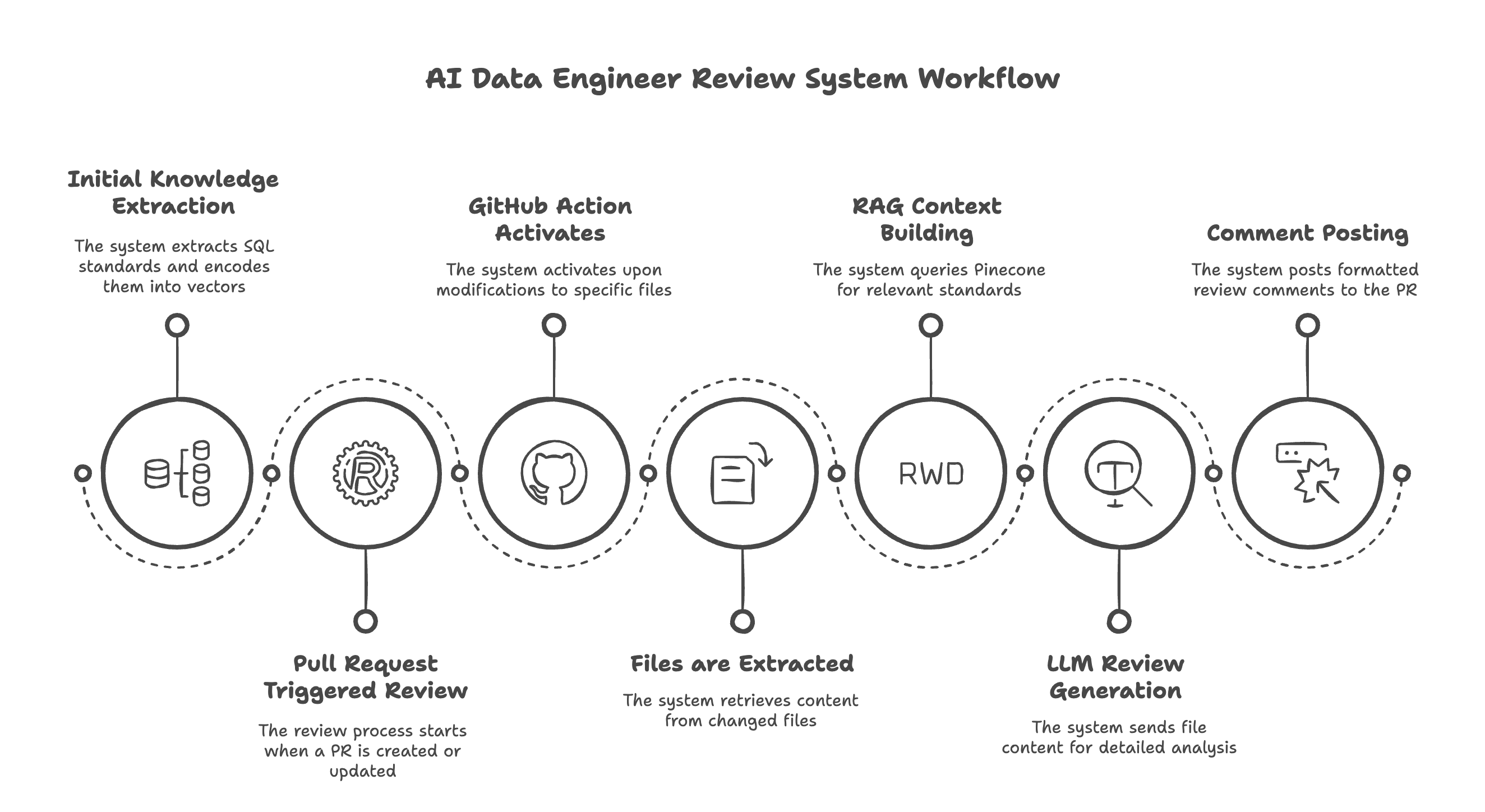
How It Works: The End-to-End Process
Let’s walk through the complete workflow of our AI Data Engineer review system:
1. Initial Knowledge Extraction
When the GitHub Action first runs on a repository, it performs these steps:
- Extracts SQL Standards: It looks for a standards document in the repository or uses default standards.
- Analyzes Existing Code: It processes a sample of SQL and DBT files to learn naming conventions and data types.
- Encodes Knowledge into Vectors: It converts all discovered patterns and standards into embeddings.
- Populates the Vector Database: It creates namespaces in Pinecone and uploads the vectors with metadata.
This creates a semantic search index that understands your codebase’s specific conventions.
2. Pull Request Triggered Review
When a developer creates or updates a Pull Request:
- GitHub Action Activates: The workflow triggers when SQL, DBT, or YAML files are modified.
- Files are Extracted: The system gets the content of each changed file.
- For Each File:
- RAG Context Building: It queries Pinecone for relevant standards and patterns based on the file content.
- LLM Review Generation: It sends the file and RAG context to the LLM for detailed analysis.
- Comment Posting: It formats the review and posts it to the PR.
3. The Developer Experience
From the developer’s perspective, the process feels seamless:
- They create a Pull Request with data engineering code changes.
- Within minutes, they receive a detailed, contextual review comment on their PR.
- The review highlights issues and suggestions specific to their organization’s standards.
- They can address the feedback before human reviewers look at the code.
4. The Review Content
The AI-generated review typically includes:
- Summary: A brief overview of the code quality
- Issues: Specific problems with line numbers and references
- Suggestions: Constructive improvements
- Proposed Tests: Data quality checks that should be added
The most powerful aspect is that these reviews reflect your organization’s actual practices, not generic rules. For example, if your team consistently uses account_number as an INT in all tables, the AI will flag inconsistencies like acct_no or VARCHAR types.
Benefits and Business Impact
Implementing an AI Data Engineer for code reviews delivers significant business value:
Immediate Impact
Improved Code Quality: Automatically enforces naming conventions, data type consistency, and SQL best practices.
Example: Reduced data pipeline errors by 42% after implementing AI-powered DBT model reviews.
Faster Code Reviews: Human reviewers can focus on business logic and architecture instead of style and conventions.
Example: Reduced PR review time from an average of 2 days to 4 hours by having the AI handle initial reviews.
Knowledge Transfer: New team members learn standards and patterns through specific, contextual feedback.
Example: New hires reach productivity milestones 3 weeks faster with AI-assisted code reviews.
Long-term Benefits
Consistency Across Teams: Enforces the same standards across distributed engineering teams and projects.
Example: Teams in two continents used AI reviews to maintain consistent data schemas across regions.
Technical Debt Prevention: Catches potential issues before they enter the codebase.
Example: Identified and fixed 85% of inefficient SQL patterns before deployment, reducing future refactoring costs.
Quality Metrics Tracking: By analyzing reviews over time, organizations can monitor trends in data quality and engineering practices.
Example: Using AI review metrics to identify that 78% of quality issues stemmed from a specific class of SQL anti-patterns, leading to targeted training.
ROI Calculation
The investment in an AI Data Engineer review system can be justified by the significant returns:
Time Savings: A team of 5 data engineers spending 1 hour each day on code reviews could save 1,250 hours annually (assuming 250 working days).
Error Reduction: Catching data quality and performance issues early prevents costly production issues. A single critical bug in a data pipeline can cost $10,000+ in engineering time and business impact.
Onboarding Efficiency: Faster knowledge transfer to new team members can save 2-3 weeks of ramp-up time per hire.
Advanced Configurations and Extensions
The base AI Data Engineer review system can be extended in several ways to make it even more powerful:
Customizing the Review Focus
You can create a configuration file in your repository to customize the AI reviewer’s behavior:
# .github/ai-reviewer-config.yml
focus_areas:
naming_conventions: high
data_types: high
performance: medium
tests: high
documentation: medium
severity_levels:
critical: ["SELECT *", "DELETE without WHERE", "Missing partition key"]
warning: ["Inconsistent naming", "No description", "Inefficient join"]
info: ["Consider alternative", "Minor formatting", "Style suggestion"]
ignored_patterns:
- "legacy/deprecated/**/*.sql"
- "**/*_test.sql"
This allows team leaders to emphasize the aspects of code quality that matter most to their organization.
Integrating with Data Documentation
Connect the AI reviewer with your data documentation tools:
def extract_documentation_context(repo):
"""Extract context from data dictionaries and documentation"""
try:
# Look for common documentation files
for doc_path in ["docs/data_dictionary.md", "definitions/tables.yml", "catalog.json"]:
try:
doc_file = repo.get_contents(doc_path)
doc_content = base64.b64decode(doc_file.content).decode("utf-8")
# Process and embed documentation content
# ...
except:
continue
except Exception as e:
logger.warning(f"Could not process documentation: {str(e)}")
This integration ensures the AI recommendations align with your documented data models and definitions.
Adding Data Quality Test Suggestions
Enhance the reviewer to propose specific DBT tests:
def suggest_dbt_tests(column_name, data_type, is_pk, is_fk, referenced_table=None):
"""Generate appropriate DBT test suggestions based on column characteristics"""
tests = []
# Always suggest not_null for primary keys
if is_pk:
tests.append(f"- not_null")
tests.append(f"- unique")
# Suggest relationship tests for foreign keys
if is_fk and referenced_table:
tests.append(f"- relationships:\n to: ref('{referenced_table}')\n field: {column_name}")
# Type-specific tests
if "date" in data_type.lower():
tests.append(f"- dbt_utils.date_in_valid_range:\n max_date: '{{ current_date() }}'")
if "amount" in column_name.lower() or "price" in column_name.lower():
tests.append(f"- dbt_expectations.expect_column_values_to_be_between:\n min_value: 0")
return tests
Creating a Dashboard of Code Quality Metrics
Build a simple tracking system for review metrics:
def track_review_metrics(pr_number, repo_name, metrics):
"""Store review metrics for trend analysis"""
timestamp = datetime.now().isoformat()
metrics_record = {
"timestamp": timestamp,
"pr_number": pr_number,
"repo_name": repo_name,
"files_analyzed": metrics["files_analyzed"],
"issues_found": metrics["issues_found"],
"naming_consistency_issues": metrics["naming_consistency_issues"],
"dbt_best_practice_issues": metrics["dbt_best_practice_issues"]
}
# In a production environment, this would write to a database
# Here we're just appending to a JSON file
try:
# Create metrics directory if it doesn't exist
os.makedirs(".metrics", exist_ok=True)
with open('.metrics/review_metrics.jsonl', 'a') as f:
f.write(json.dumps(metrics_record) + "\n")
except Exception as e:
logger.error(f"Error storing metrics: {str(e)}")
This data can be visualized in a simple dashboard to track code quality trends over time.
Conclusion and Next Steps
In this article, we’ve taken the theoretical foundations of LLMs, RAG, and vector databases from Part 1 and implemented them in a practical, high-value system that can transform your data engineering workflow. By creating an AI Data Engineer for code reviews, we’re addressing the common challenges of maintaining code quality, consistency, and best practices across data engineering teams.
The power of this approach comes from combining:
- Contextual Intelligence: The AI understands your specific codebase, not just generic standards
- Semantic Understanding: Vector embeddings enable the system to find similar patterns even when exact matches don’t exist
- RAG Architecture: The LLM’s reasoning capabilities are grounded in your organization’s actual practices
- GitHub Integration: The system fits seamlessly into existing development workflows
Getting Started
To implement this in your organization:
- Start Small: Begin with a single repository and a focused set of standards
- Collect Feedback: Ask your team which aspects of the reviews are most helpful
- Iterate: Refine the prompts and vector database to improve relevance
- Measure Impact: Track metrics like PR cycle time and bug reduction
Where to Go Next
As you become comfortable with the base implementation, consider these extensions:
- Multi-Agent Reviews: Add specialized agents for security, performance, and business logic
- Interactive Suggestions: Enable the AI to propose specific fixes that can be applied with one click
- Natural Language Interfaces: Allow engineers to ask the AI questions about data models and transformations
- Knowledge Management: Use the vector database as a foundation for a broader data engineering knowledge system
The possibilities are limited only by your imagination. The core technology stack we’ve implemented—LLMs with RAG capabilities and vector databases—can be applied to numerous data engineering challenges beyond code reviews.
By combining these advanced AI capabilities with your team’s domain expertise, you can create a powerful system that accelerates development, improves quality, and makes your data engineering practice more robust and consistent.
Remember: The goal isn’t to replace human judgment but to augment it—freeing your team to focus on the creative and strategic aspects of data engineering while the AI handles the routine checks and reinforces your best practices.