
Chris Hillman
Friday, March 7, 2025
Leveraging LLMs for Business Impact: Part 1 - Theory and Foundations
Introduction
In today’s rapidly evolving technological landscape, Large Language Models (LLMs) have emerged as transformative tools with the potential to revolutionize business operations across industries. While the hype around these technologies is intense, understanding their practical applications and underlying mechanisms is crucial for organizations seeking to leverage them effectively.
This two-part series aims to demystify LLMs and their associated technologies, starting with the theoretical foundations in Part 1, followed by a hands-on implementation guide using AWS services in Part 2.
Understanding Large Language Models (LLMs)
What Are LLMs?
Large Language Models are sophisticated AI systems trained on vast amounts of text data to understand and generate human-like language. Unlike traditional rule-based systems, LLMs learn patterns and relationships within language, enabling them to perform a wide range of tasks - from answering questions and summarizing content to translating languages and generating creative text.
Modern LLMs like GPT-4, Claude, and Llama 2 can reason, infer, and adapt to different contexts with remarkable flexibility. These models have billions or even trillions of parameters (adjustable values that the model learns during training), allowing them to capture nuanced linguistic patterns and knowledge.
LLM Capabilities and Limitations
LLMs excel at:
- Language understanding and generation: Comprehending complex queries and producing coherent, contextually appropriate responses
- Knowledge retrieval: Accessing information they’ve been trained on
- Task adaptation: Applying language skills to various domains with minimal explicit instruction
- Pattern recognition: Identifying trends and relationships within text
However, they face key limitations:
- Hallucination: Sometimes generating plausible-sounding but factually incorrect information
- Knowledge cutoff: Limited to information available up to their training cutoff date
- Context window constraints: Only able to “see” a finite amount of text at once
- Reasoning limitations: Struggling with complex logical or mathematical reasoning
- Lack of domain-specific knowledge: Generic models often lack deep expertise in specialized fields
These limitations are particularly relevant in business contexts where accuracy and reliability are paramount. This is where Retrieval Augmented Generation (RAG) and vector databases come in.
Retrieval Augmented Generation (RAG): Enhancing LLMs with External Knowledge
The RAG Framework
RAG represents a paradigm shift in how we interact with LLMs by combining retrieval systems with generative AI. At its core, RAG works by:
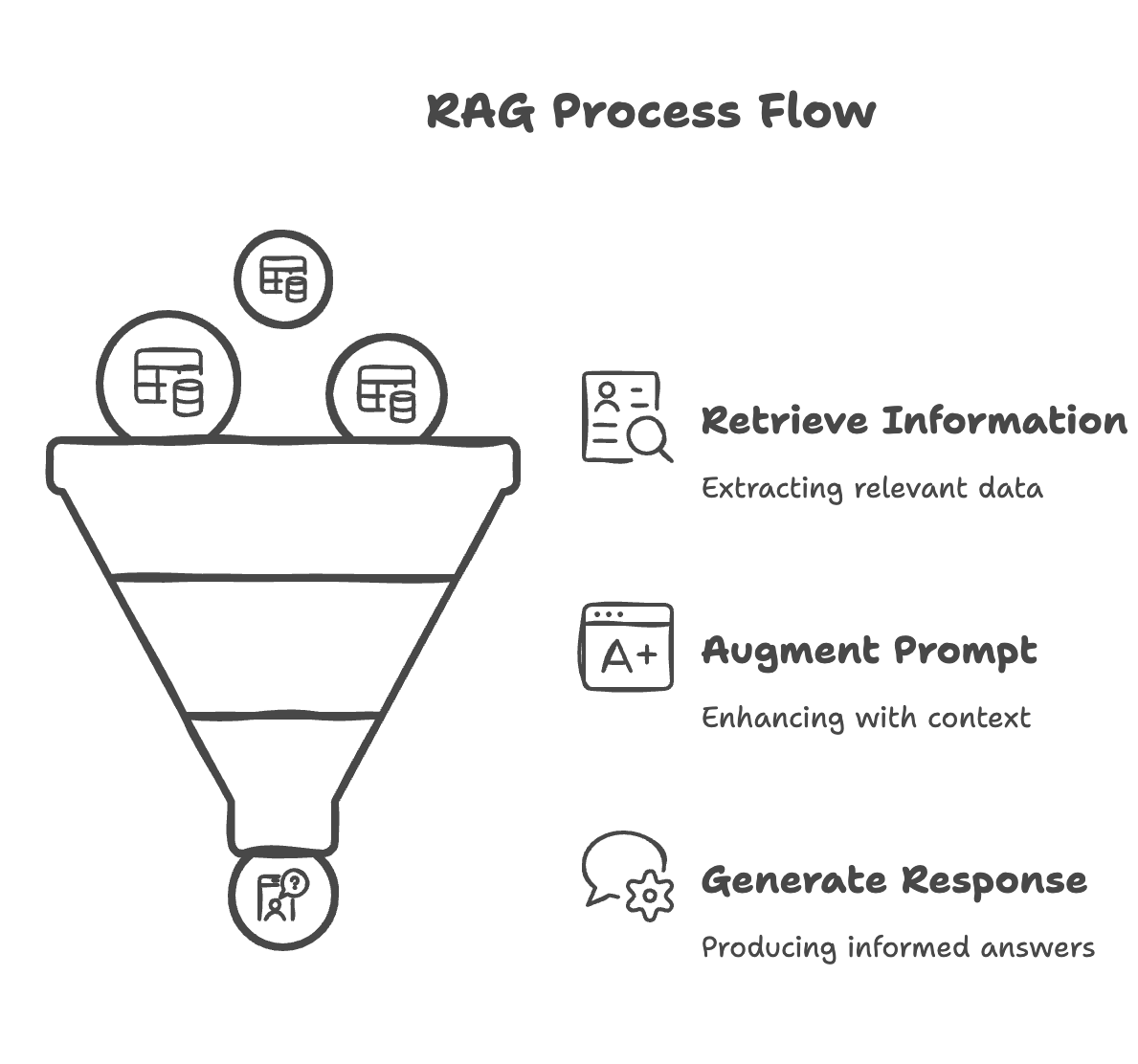
- Retrieving relevant information from a knowledge base
- Augmenting the LLM’s prompt with this contextual information
- Generating responses informed by both the model’s parametric knowledge and the retrieved information
This approach addresses several key LLM limitations:
- Improves factual accuracy by grounding responses in verified information
- Extends knowledge beyond training cutoff by incorporating up-to-date information
- Enables domain-specific expertise through specialized knowledge bases
- Creates auditability by tracking sources of information
LLMs alone might lack knowledge of specific company data architectures, but RAG can bridge this gap. By integrating company documentation, data dictionaries, and past incident reports into a vector database, engineers can query a system that retrieves relevant knowledge before generating responses.
Example: A data engineer is troubleshooting a failing data pipeline in an AWS Glue job. Instead of searching through Confluence pages or old Slack threads, they ask an LLM-powered assistant: “Why is my Glue job failing with an ‘out of memory’ error?”
The RAG-powered assistant:
Retrieves past incident reports where engineers faced similar issues. Finds a company-specific best practices document on Glue memory tuning. Generates a recommendation based on both the retrieved knowledge and general LLM expertise. This saves hours of manual searching and accelerates issue resolution.
The RAG Pipeline
A typical RAG implementation involves several key steps:
- Document ingestion: Processing and chunking documents into manageable pieces
- Embedding generation: Converting text chunks into vector embeddings
- Vector storage: Storing these embeddings in a vector database
- Query processing: Converting user queries into the same vector space
- Similarity search: Finding the most relevant documents based on vector similarity
- Context augmentation: Adding retrieved information to the LLM prompt
- Response generation: Using the enhanced prompt to generate an informed response
This architecture provides businesses with the flexibility to incorporate proprietary knowledge, specialized datasets, and real-time information into their AI systems.
Vector Databases: The Engine Behind Semantic Search
What Are Vector Databases?
Vector databases are specialized storage systems designed to efficiently store, index, and query high-dimensional vectors (mathematical representations of data). Unlike traditional databases that excel at exact matches, vector databases are optimized for similarity searches - finding items that are conceptually similar rather than identical.
In the context of LLMs and RAG, vector databases store embeddings - numerical representations of text that capture semantic meaning. These embeddings allow us to find information based on conceptual similarity rather than keyword matching.
Key Components and Characteristics
Vector databases have several distinctive features:
- Vector embeddings: Numerical representations (typically 768-4096 dimensions) that encode semantic meaning
- Similarity metrics: Methods for measuring the “closeness” of vectors (cosine similarity, Euclidean distance)
- Indexing structures: Specialized algorithms (HNSW, IVF, etc.) that enable efficient similarity search
- Metadata storage: Additional information about each vector for filtering and retrieval
- Scalability features: Capabilities for handling billions of vectors across distributed systems
Popular vector database implementations include:
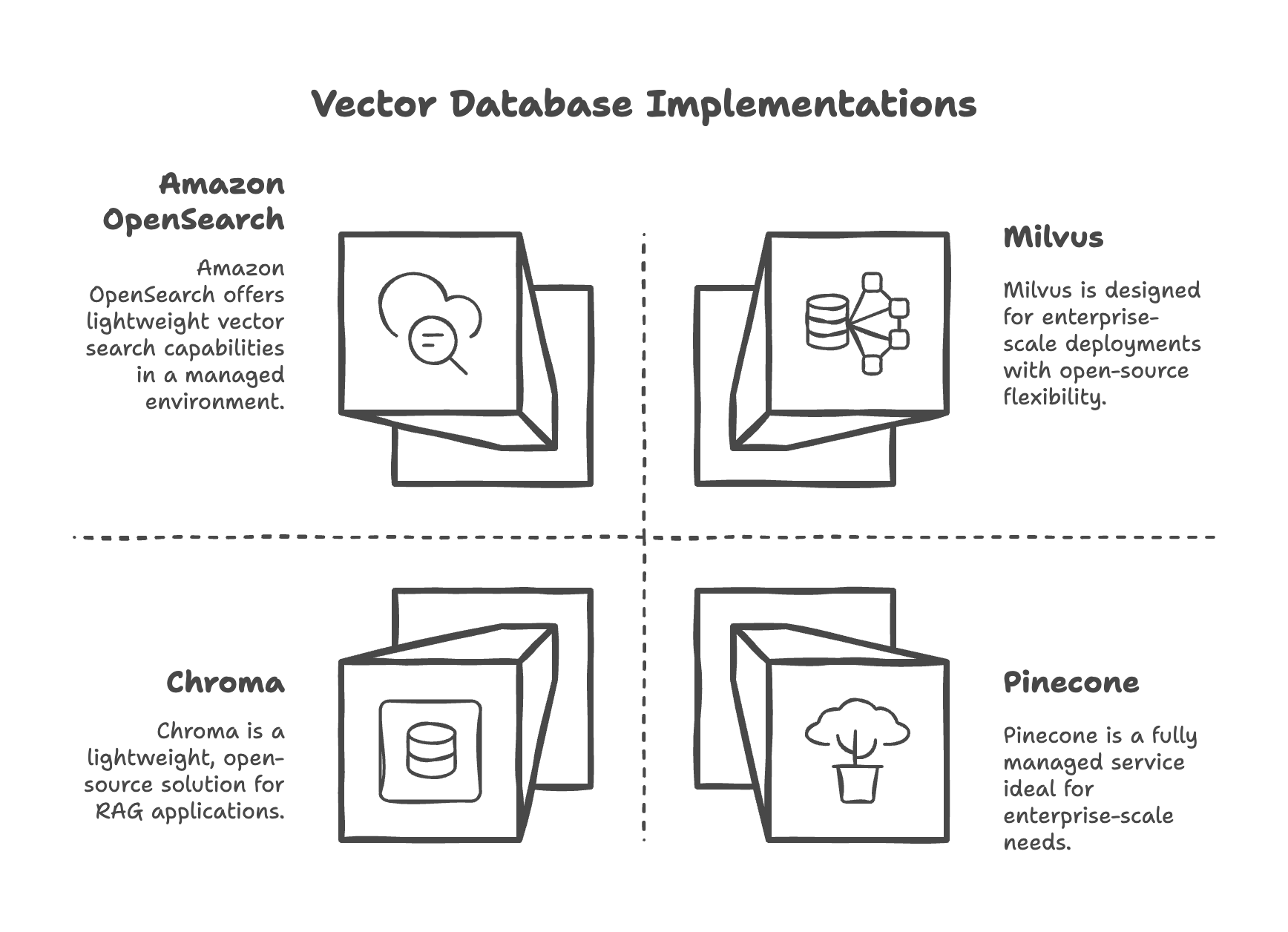
- Pinecone: Fully managed vector database service
- Weaviate: Open-source vector search engine
- Chroma: Lightweight embedding database for RAG applications
- Milvus: Open-source vector database built for enterprise-scale deployments
- FAISS (Facebook AI Similarity Search): Library for efficient similarity search
- Amazon OpenSearch: Service with vector search capabilities
How Vector Databases Work
At a fundamental level, vector databases solve the nearest neighbor search problem - given a query vector, find the most similar vectors in the database. However, as the number of dimensions and vectors grows, this becomes computationally expensive.
Vector databases employ approximate nearest neighbor (ANN) algorithms that trade perfect accuracy for dramatic performance improvements. These approaches include:
- Hierarchical Navigable Small World (HNSW): Creates a multi-layered graph structure for efficient navigation
- Inverted File Index (IVF): Partitions the vector space into clusters for faster search
- Product Quantization (PQ): Compresses vectors to reduce memory usage while preserving similarity characteristics
These technical optimizations enable systems to search millions or billions of vectors in milliseconds, making real-time RAG applications possible.
The Synergy: How These Technologies Work Together
The real power emerges when LLMs, RAG, and vector databases operate as an integrated system:
- Knowledge Base Creation:
- Documents are processed, chunked, and converted to embeddings
- These embeddings, along with metadata, are stored in a vector database
- The system builds efficient indexes for fast retrieval
- Query Processing:
- A user submits a query
- The query is embedded into the same vector space
- The vector database finds semantically similar content
- Relevant information is retrieved and formatted
- Enhanced Response Generation:
- The LLM receives both the original query and retrieved information
- The model generates a response that incorporates this external knowledge
- The system can cite sources, explain reasoning, and provide verifiable information
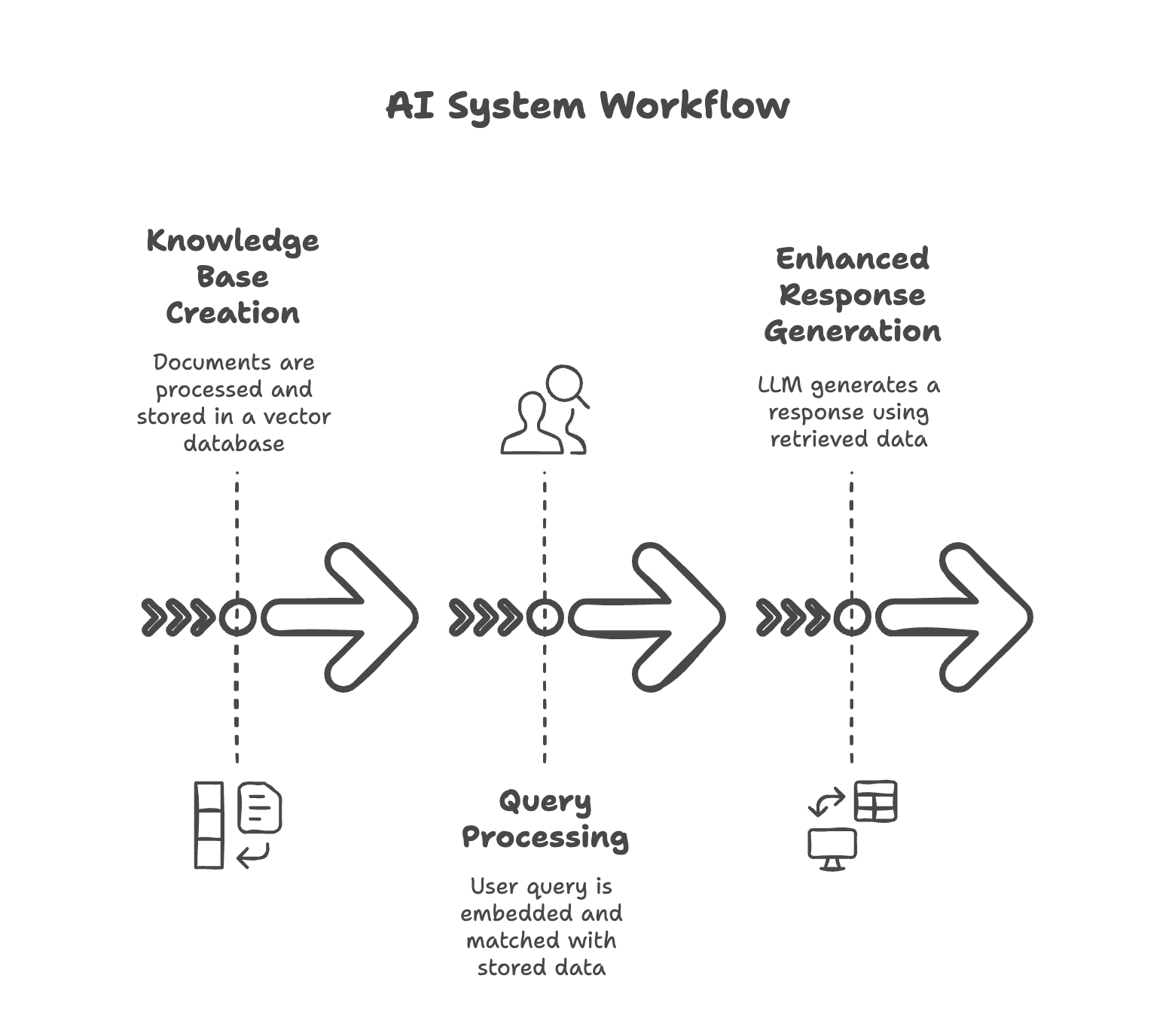
This architecture represents a significant advancement over standalone LLMs, enabling businesses to leverage their proprietary knowledge while benefiting from the reasoning capabilities of foundation models.
Business Implications and Applications
Transform Business Processes
LLMs with RAG can transform numerous business functions:
- Customer Support: Creating AI assistants that can access product documentation, support tickets, and knowledge bases to resolve customer issues
- Content Creation: Generating marketing materials, reports, and documentation informed by brand guidelines and product details
- Legal and Compliance: Answering questions based on regulatory documents, contracts, and policies
- Research and Development: Summarizing research papers and identifying patterns across technical literature
- Knowledge Management: Making organizational knowledge accessible and actionable
Training and Upskilling New Data Engineers
LLMs can be used as interactive mentors for new data engineers by providing:
- Code Walkthroughs: Junior engineers can input a piece of SQL, Python, or Spark code, and an LLM can break it down, explaining best practices, inefficiencies, or potential pitfalls.
- Data Pipeline Debugging: An LLM-based assistant can suggest fixes when encountering issues in ETL processes.
- Documentation Generation: Automatically generate documentation for a given data pipeline based on code and metadata, reducing the manual effort required.
Example: A new data engineer at a financial services company is tasked with optimizing a slow SQL query running against a large Postgres database. They submit their query to an LLM-powered assistant, which:
Identifies missing indexes and suggests improvements. Recognizes inefficient JOIN operations and proposes alternatives. Provides a step-by-step execution plan analysis, teaching the engineer how to optimize queries themselves in the future.
Peer Reviewing Initial Code Submissions
LLMs can assist in the code review process by:
- Checking for errors: Identifying syntax issues, anti-patterns, or security risks in Python, SQL, or Scala.
- Ensuring adherence to style guides: Comparing code against company-specific best practices and formatting guidelines.
- Providing alternative solutions: Suggesting more efficient ways to write transformation logic or queries.
Example: A data engineering team at an e-commerce company uses an LLM-integrated CI/CD tool that automatically reviews every pull request. When a junior engineer submits a PySpark script for processing customer orders, the LLM:
Flags an inefficient groupBy() operation that causes excessive shuffling. Suggests an alternative reduceByKey() approach for better performance. Explains why the change is beneficial, reinforcing best practices.
Multi-Agent Systems for Enhanced Reliability
One of the most promising approaches to mitigating hallucinations and improving LLM reliability is the implementation of multi-agent systems. These systems leverage multiple LLM instances working together to verify outputs and catch errors.
How Multi-Agent Systems Work
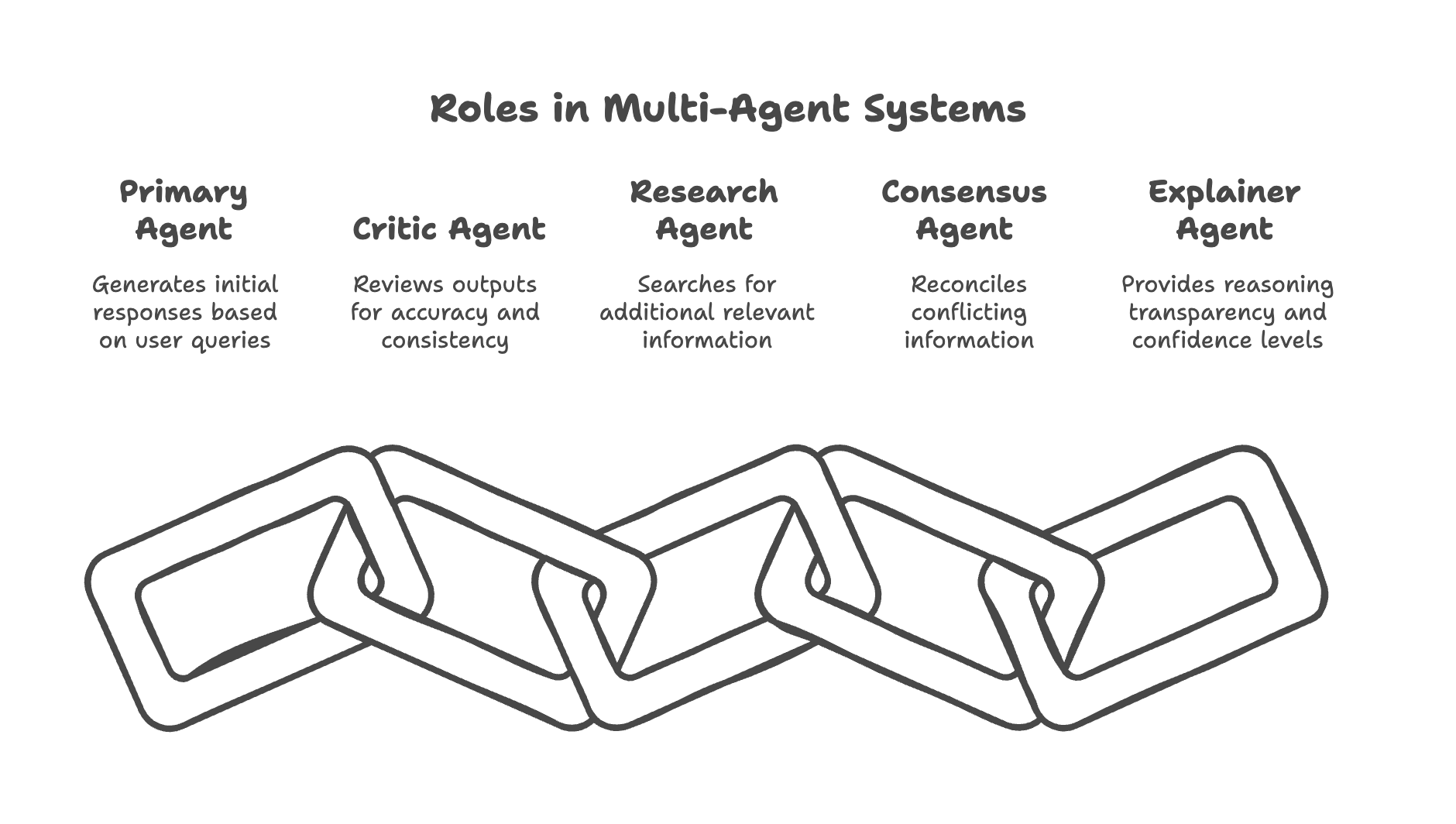
Multi-agent systems typically involve several specialized roles:
- Primary Agent: Generates initial responses based on user queries and retrieved context
- Critic Agent: Reviews the primary agent’s output for factual accuracy, hallucinations, and logical inconsistencies
- Research Agent: Actively searches for additional relevant information when knowledge gaps are identified
- Consensus Agent: Reconciles potentially conflicting information from multiple sources
- Explainer Agent: Provides reasoning transparency and confidence levels for final outputs
Hallucination Mitigation Through Peer Review
Multi-agent systems reduce hallucinations through several mechanisms:
- Distributed Verification: Each agent independently verifies information, creating a system of checks and balances
- Specialized Expertise: Agents can be fine-tuned for specific domains or tasks, improving accuracy in their areas of focus
- Explicit Reasoning Chains: Agents are required to explain their reasoning process, making erroneous logic easier to detect
- Confidence Scoring: Systems can implement confidence metrics, flagging uncertain statements for human review
- Adversarial Testing: Specifically designed agents can challenge assertions made by other agents, testing their validity
Implementation Considerations
Organizations considering RAG implementations should evaluate:
- Data suitability: Whether existing documents are structured appropriately for RAG
- Embedding strategy: Which embedding models and chunking approaches to use
- Security and privacy: How to handle sensitive information
- Infrastructure requirements: Computing resources needed for embeddings and inference
- Evaluation frameworks: Methods for measuring system accuracy and effectiveness
The Business Impact Opportunity
When properly implemented, these systems can deliver significant business value:
- Reduced operational costs through automation of information-intensive tasks
- Enhanced decision-making by making relevant information readily accessible
- Improved customer experiences through more accurate and helpful AI interactions
- Accelerated innovation by helping employees leverage institutional knowledge
- Competitive differentiation through personalized and contextually aware services
Conclusion: Preparing for Implementation
The theoretical understanding of LLMs, RAG, and vector databases provides the foundation for practical implementation. Organizations that grasp these concepts can make informed decisions about how to leverage these technologies effectively.
As with any transformative technology, the organizations that will benefit most are those that approach implementation thoughtfully, with clear business objectives and a solid understanding of the underlying mechanisms. By combining the generative capabilities of LLMs with the factual grounding of RAG and the efficient retrieval of vector databases, businesses can create AI systems that are not just impressive demonstrations but valuable tools that drive tangible business impact.