
Chris Hillman
Saturday, February 17, 2024
Optimizing CI/CD with SlimCi DBT for Efficient Data Engineering
Introduction
In the rapidly evolving landscape of software development and data engineering, the ability to adapt and respond to changes quickly is not just an advantage; it’s a necessity.
One of the core practices enabling this agility is Continuous Integration (CI), a methodology that encourages developers to integrate their work into a shared repository early and often. At its heart, CI embodies the “fail fast” principle, a philosophy that values early detection of errors and inconsistencies, allowing teams to address issues before they escalate into more significant problems.
Im going to go over how I applied Continuous Integration, using Codefresh and dbt (data build tool). I am not a DevOps specialist, so if you notice any way of doing things differently, please let me know - would love to learn from your experiences.
Setting Up the Environment
Before diving into the intricacies of Continuous Integration with Codefresh and dbt, it’s essential to lay the groundwork by setting up our development environment. This setup is crucial for ensuring a smooth workflow and maximising the benefits of CI practices.
GitHub Repository Configuration
Our journey kicks off with GitHub, serving as the cornerstone for our version control. It facilitates not just code hosting but also enhances collaboration and streamlines the review and integration workflows. Here’s the step-by-step guide:
- Initialize a New Repository: Create a new GitHub repository to host your project’s assets, including dbt models, tests, and CI/CD configurations.
- Clone Locally: After setting up your repository, clone it to your local environment using the git clone command followed by your repository’s URL.
- Initial Commit: Begin with an initial commit, possibly including a basic project scaffold or a README file, to establish the version history outset.
Post GitHub configuration, integrate a sample dbt project. We recommend starting with the dbt-labs/jaffle-shop for a structured example, ensuring to adapt it to your project’s specifics.
Docker Environment Setup
Incorporate a Dockerfile into your repository, which Codefresh will utilize to craft an environment for dbt execution:
Make sure to replace**
Initializing Your Project in Codefresh
To kickstart your CI/CD journey with Codefresh, begin by creating a new project within the platform, followed by setting up a new pipeline. This pipeline will be linked to the GitHub repository you prepared earlier, which houses your dbt project and Dockerfile.
Configuring Your Pipeline Workflow
Within Codefresh, configure your pipeline using a YAML file to define the workflow stages and steps. Here’s an enhanced example incorporating best practices:
Insure to replace
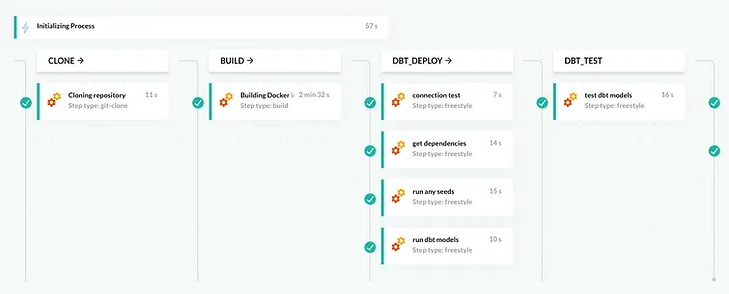
Finalizing and Testing Your Pipeline
After setting up your pipeline, save the configuration and initiate a test run to verify its functionality. Fine-tune the workflow as needed based on the outcomes of these tests.
Automating Pipeline Triggers
To fully leverage CI/CD, set up a trigger within Codefresh that responds to GitHub events (e.g., commits, pushes, tags). Specify the type of trigger as ‘Git’, and link it to your repository. Codefresh will provide an endpoint and a secret for this purpose.

Subsequently, navigate to your GitHub repository settings, find the ‘Webhooks’ section, and add a new webhook using the details provided by Codefresh. This integration ensures that any specified GitHub event will automatically initiate your Codefresh pipeline, streamlining your development and deployment processes.
Optimizing dbt Runs with State Management and SlimCI
After setting up the basic CI/CD pipeline in Codefresh, we’ll introduce an advanced technique to optimise dbt runs using state management and Slim CI. This method significantly reduces build times by only running models that have changed since the last successful state.
Saving dbt State with dbt Compile:
To save the current state of your dbt project, you’ll use the dbt compile command with a specific target that defines your environment settings.
This step generates compiled SQL files and project documentation, capturing the project’s current state.
Run the following step locally, and commit it to your Github Repository to save it’s current state.
Replace <your_target> with your actual target environment as defined in your** dbt_project.yml** or profiles.yml.
Implementing Slim CI with dbt:
Slim CI is a feature provided by dbt that allows you to run only the models that have changed since the last successful run, based on the state artifacts. To utilize Slim CI, you’ll need to use the dbt run command with the –state flag pointing to your saved state artifacts.
Update the dbt-run step in your pipeline to include Slim CI logic:
Ensure to replace /path/to/saved/state with the actual path where your dbt state artifacts are stored. This path should be accessible within your Codefresh pipeline environment.
You can repeat this for dbt test step as well.
Finalizing Your Pipeline Configuration:
With Slim CI integration, your pipeline is now optimized to only rebuild and test models affected by recent changes. This setup significantly reduces build times and resource consumption, making your CI/CD process more efficient.
Save your updated pipeline configuration and conduct a test run to ensure everything works as expected. Adjustments may be necessary based on the specifics of your dbt project and Codefresh environment.
By incorporating dbt state management and leveraging Slim CI, your Codefresh pipeline becomes more efficient, focusing only on the changes that matter for each build. This approach not only speeds up your CI/CD process but also ensures that your resources are used judiciously, leading to faster feedback cycles and more agile development practices.
Adding in the –defer flag
The –defer flag is used in conjunction with dbt’s state management features to facilitate incremental development and testing. When used with dbt run or dbt test, the –defer flag tells dbt to use the results from a previous run (from a different target) for models that have not changed.
This is particularly useful in CI/CD pipelines and development workflows where you want to test changes without fully rebuilding or re-running all models.
For instance, if you’re working on a feature branch and want to test your changes against the production data without affecting production models, you can use –defer along with the –state flag to refer to the production state. This way, dbt will use the existing production models for any unchanged parts of your project, and only apply your changes to the models you’ve modified.
To use –defer, you need to ensure that:
- You have access to the artifacts (typically found in the target/ directory) from the previous run of the models you’re deferring to.
- You specify the –state flag to point to the directory where these artifacts are located.
- You indicate the target that represents the environment you’re deferring to (e.g., production).
An example command might look like this:
This command tells dbt to run models in the dev environment while deferring to the state of models in the prod environment for any unchanged models.
In summary, using –target allows you to specify which environment configurations to use during your dbt run, and –defer enables you to build upon the state of models from a previous run, optimizing your development and testing processes by reducing unnecessary computation and preserving the integrity of your data.
Codefresh offers a great starting point for CI/CD in dbt projects. The world of data pipeline automation is vast, with continuous advances in tooling and best practices. As your data transformation projects mature, consider exploring areas like data quality testing, advanced deployments, and automated documentation generation to continuously improve the robustness and maintainability of your pipelines.
It’s an exciting journey – have fun experimenting!