
Chris Hillman
Sunday, January 14, 2024
Delta-lake - Z-Ordering, Z-Cube, Liquid Clustering and Partitions
Introduction
Ever feel like your data lake is more of a data swamp, swallowing queries whole and spitting out eternity? You’re not alone. Managing massive datasets can be a Herculean task, especially when it comes to squeezing out those precious milliseconds of query performance. But fear not, data warriors, for Delta Lake has hidden treasures waiting to be unearthed: Z-ordering, Z-cube, and liquid clustering.
Partition Pruning: The OG Hero
Before we dive into these exotic beasts, let’s pay homage to the OG hero of data organization: partition pruning. Imagine your data lake as a meticulously organized library, with each book (partition) shelved by a specific topic (partition column). When a query saunters in, it doesn’t have to wander through every aisle. It simply heads straight for the relevant section, drastically reducing the time it takes to find what it needs. That’s the magic of partition pruning!
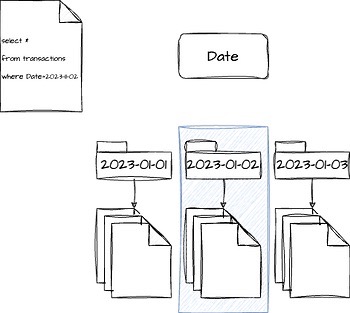
Z-Ordering: The Spatial Sensei
But what happens when your library’s shelves are spread across multiple buildings? Z-ordering enters the scene, a master of spatial organization. It takes related information, like books on similar subjects, and arranges them close to each other, even across different buildings. This means your queries can zip between relevant data like a parkour ninja, saving precious time.
Example - PySpark
import pyspark.sql.functions as F
from delta.tables import *
# Create a SparkSession spark = SparkSession.builder.appName("ZOrderingExample").getOrCreate()
# Read the dataset from a Delta table (or load from a source like CSV) data = spark.read.format("delta").load("/path/to/your/delta/table")
# Apply Z-ordering on the "date" and "user_id" columns zOrderedData = data.write.format("delta") \
.mode("overwrite") \
.option("ZOrderBy", "date, user_id") \
.save("/path/to/zOrderedDataset")
# Query the Z-ordered table, filtering by date and user_id query = zOrderedData.filter(F.col("date") == "2024-01-15" and F.col("user_id") > 1000) query.show()
# To optimize an existing Delta table with Z-ordering:
optimize(spark, "/path/to/zOrderedDataset", "ZORDER BY date, user_id")
Example - SQL
-- Create a Z-ordered Delta table:
CREATE TABLE z_ordered_table
USING DELTA
PARTITIONED BY (date)
ZORDER BY (user_id)
AS SELECT * FROM original_table;
-- Optimize an existing Delta table with Z-ordering:
ALTER TABLE original_table OPTIMIZE ZORDER BY (date, user_id);
Z-Cube: The Multi-Dimensional Mastermind
Not all libraries are simple one-dimensional rows, though. Some house intricate collections with multiple dimensions, like a museum showcasing art from different eras and regions. Z-cube, the multi-dimensional mastermind, comes to the rescue here. It maps your data onto a multi-dimensional grid, ensuring that art pieces from similar eras and regions are always close neighbors. Your complex queries can now navigate this grid with ease, finding the treasures they seek in a flash.
Example - PySpark
import pyspark.sql.functions as F
from delta.tables import *
# Create a SparkSession
spark = SparkSession.builder.appName("ZCubeExample").getOrCreate()
# Read the dataset
data = spark.read.format("delta").load("/path/to/your/delta/table")
# Apply Z-Cube on the "category", "brand", and "price" columns
zCubeData = data.write.format("delta") \
.mode("overwrite") \
.option("ZCube", "category, brand, price") \
.save("/path/to/zCubeDataset")
# Query the Z-Cube table, filtering across multiple dimensions
query = zCubeData.filter(F.col("category") == "Electronics" and
F.col("brand").isin(["Apple", "Samsung"]) and
F.col("price") > 500)
query.show()
# To optimize an existing Delta table with Z-Cube:
optimize(spark, "/path/to/zCubeDataset", "ZCube BY category, brand, price")
Example - SQL
-- Create a Z-Cube Delta table:
CREATE TABLE z_cube_table
USING DELTA
PARTITIONED BY (category)
ZORDER BY (brand, price)
AS SELECT * FROM original_table;
-- Optimize an existing Delta table with Z-Cube:
ALTER TABLE original_table OPTIMIZE ZORDER BY (category, brand, price);
Liquid Clustering: The Evolving Adaptor
But what if the library’s collection keeps growing and changing? Enter liquid clustering, the ever-adapting chameleon of data organization. It continuously analyzes your data, grouping similar items together and reshuffling them as new information arrives. Think of it as a librarian constantly rearranging shelves to keep up with the latest acquisitions. This dynamic approach is perfect for datasets in constant flux, ensuring queries always have the most efficient path to their targets.
Example - PySpark
import pyspark.sql.functions as F
from delta.tables import *
# Create a SparkSession
spark = SparkSession.builder.appName("LiquidClusteringExample").getOrCreate()
# Read the dataset
data = spark.read.format("delta").load("/path/to/your/delta/table")
# Enable liquid clustering on the desired columns
data.write.format("delta") \
.option("clustering", "user_id, sentiment") \
.save("/path/to/liquidClusteredDataset")
# To optimize an existing Delta table with liquid clustering:
optimize(spark, "/path/to/liquidClusteredDataset", "clustering user_id, sentiment")
Note: Limited to Databricks runtime as of Jan 2024
Choosing Your Weapon: The Data Lake Dojo
So, which data organization warrior should you choose? Don’t worry, we’ve got your back! Z-ordering shines when you have a few key filter columns and predictable data patterns. Z-cube thrives in multi-dimensional data realms with complex queries. And liquid clustering adapts like a ninja to ever-changing datasets.
Further Reading and Resources
Z-Ordering:
- Delta Lake Optimization Guide: Provides detailed explanations of Z-ordering, including benefits, limitations, and configuration options.
- Space-Filling Curves for Data Organization: Research paper delving into the mathematical aspects of Z-curves and their applications in data organization.
Z-Cube:
- Delta Lake Summit 2023 Presentation: Slide deck includes detailed explanations and diagrams of Z-cube.
- Multi-Dimensional Data Indexing Using Space-Filling Curves: Databricks blog post with technical discussion and illustrations of Z-cube.
Liquid Clustering:
- Delta Lake 2.0: What’s New and Exciting: Databricks blog post introducing liquid clustering with conceptual explanations and demos.
- Dynamic Data Partitioning for Evolving Datasets: TechTarget article discussing concepts similar to liquid clustering with illustrative diagrams.